6 Regresijska analiza
6.1 Korelacije
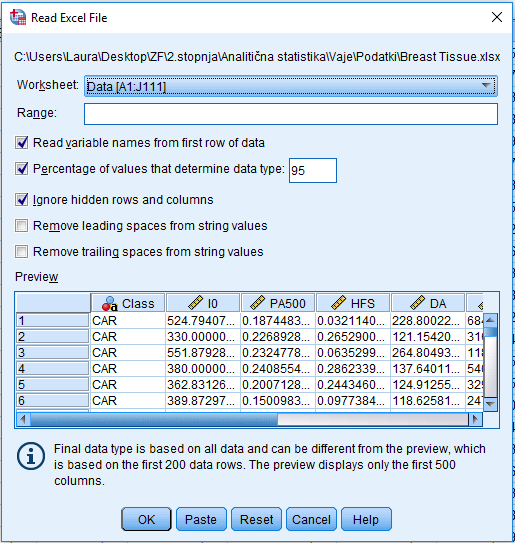
V Excel datoteki imamo različne meritve, ki jih dobimo pri impedančni spektroskopiji. Uvozimo jih v SPSS: File -> Import data -> Excel … izberemo datoteko Breast Tissue.xls in izberemo Open. Za uvoz podatkov izberemo drugi list v Excelovi datoteki: Worksheet: Data.
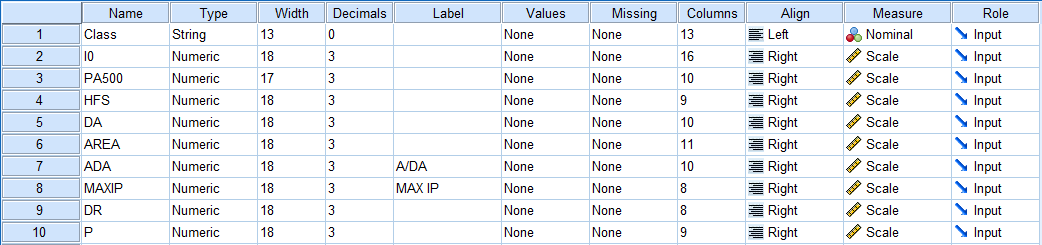
V Variable View pri vseh spremenljivkah zmanjšamo število decimalk na tri decimalna mesta, da bodo podatki bolj pregledni. Slika prikazuje zavihek Variable View.
Želimo ugotoviti katere spremenljivke so tako imenovani kofaktorji. To so spremenljivke, ki so korelacijsko povezane. Narišemo graf medsebojnih odvisnosti za vse pare meritev.
Graphs -> Graphboard template chooser. Nato označimo vse skalarne spremenljivke IO, PA500, HFS, DA, AREA, A/DA, MAX IP, DR, P tako, da izberemo prvo, držimo tipko Shift in izberemo zadnjo. Z izbiro teh spremenljivk nam program ponudi dva možna grafa in izberemo Scatterplot Matrix (SPLOM) ter potrdimo.
V izvedbenem oknu se nam izriše matrika grafov kombiniranih za vse pare meritev.
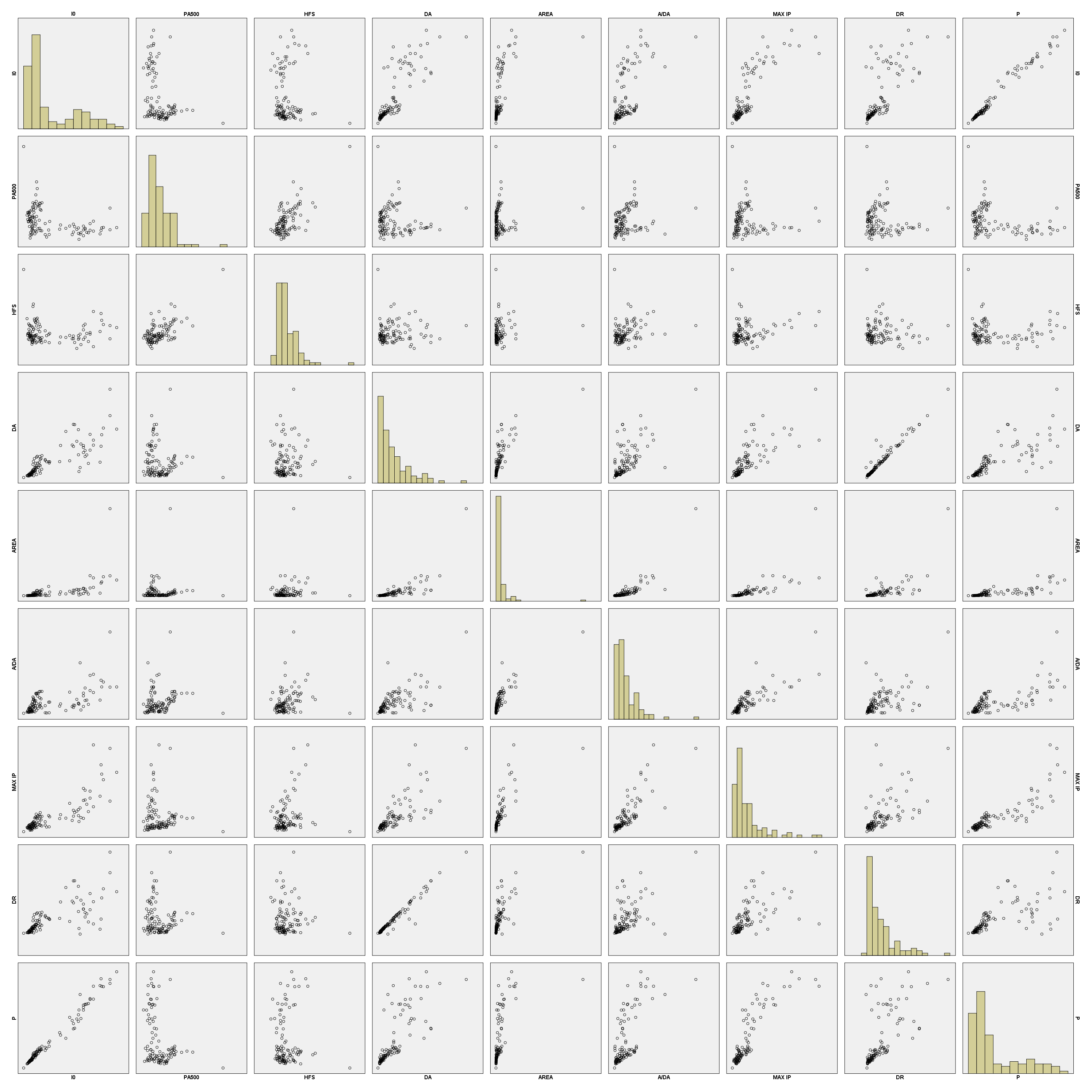
Poglejmo na primer, kako je spremenljivka P korelirana z ostalimi spremenljivkami (gledamo zadnjo vrstico matrike, na slikah so prikazani posamezni odseki):
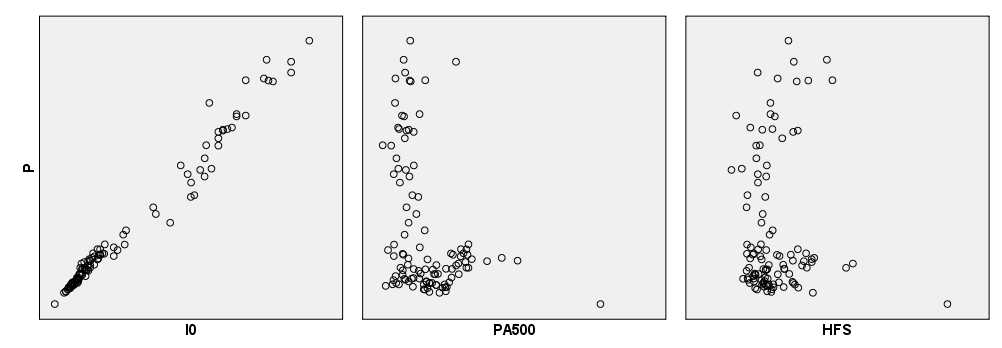
Spremenljivki P in IO sta močno korelirani in sicer linearno, saj lahko na graf položimo premico, ki se približno prilega podatkom. Spremenljivki P in PA500 nista korelirani. Spremenljivki P in HFS nista korelirani.
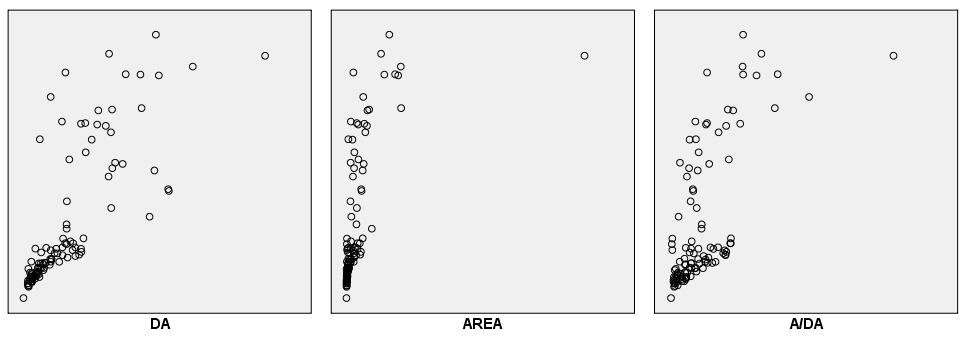
Spremenljivki P in DA sta korelirani, vendar ne nujno linearno. Spremenljivki P in AREA sta korelirani in sicer močno navzgor. Pri tej povezavi imamo en izrazit odstopajoči par meritev. Spremenljivki P in A/DA sta korelirani.
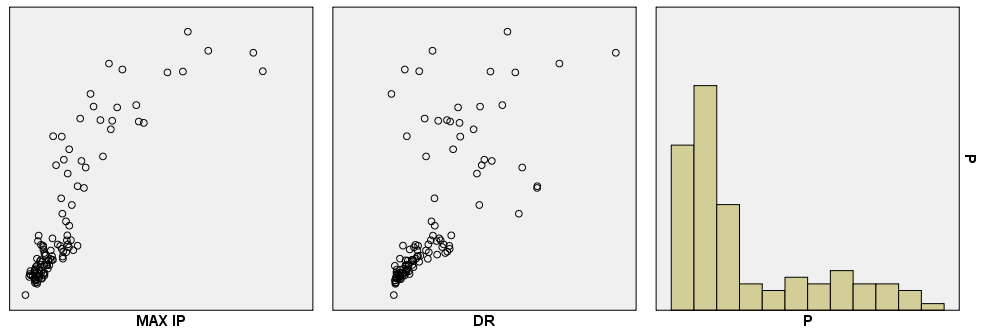
Spremenljivki P in MAX IP sta korelirani. Spremenljivki P in DR sta korelirani. Zadnji graf je histogram, saj se ista spremenljivka ne more primerjati s sabo. Zato je narisana porazdelitev te spremenljivke.
Korelacijo potrdimo, ko lahko na graf položimo krivuljo, ki se približno prilega meritvam. Nekaj korelacij opazimo takoj, nekatere pa niso očitne, oziroma jih ni.
Za ugotavljanje povezanosti spremenljivk in sicer linearno povezanih z normalno porazdelitvijo bomo uporabili Pearsonovo korelacijo. Spearmanova korelacija meri nelinearno povezanost spremenljivk, če podatki niso normalno porazdeljeni.
Analyze -> Correlate -> Bivariate. Za analizo izberemo vse spremenljivke: IO, PA500, HFS, DA, AREA, A/DA, MAX IP, DR, P ter označimo korelacijska koeficienta Pearson in Spearman.
V izvedbenem oknu dobimo rezultate. Oznaka * nam pove, da je korelacija statistično značilno različna od 0, vrednost korelacije pa koliko sta spremenljivki povezani oz. korelirani. Poglejmo najprej tabelo Pearsonovih koeficientov korelacije:
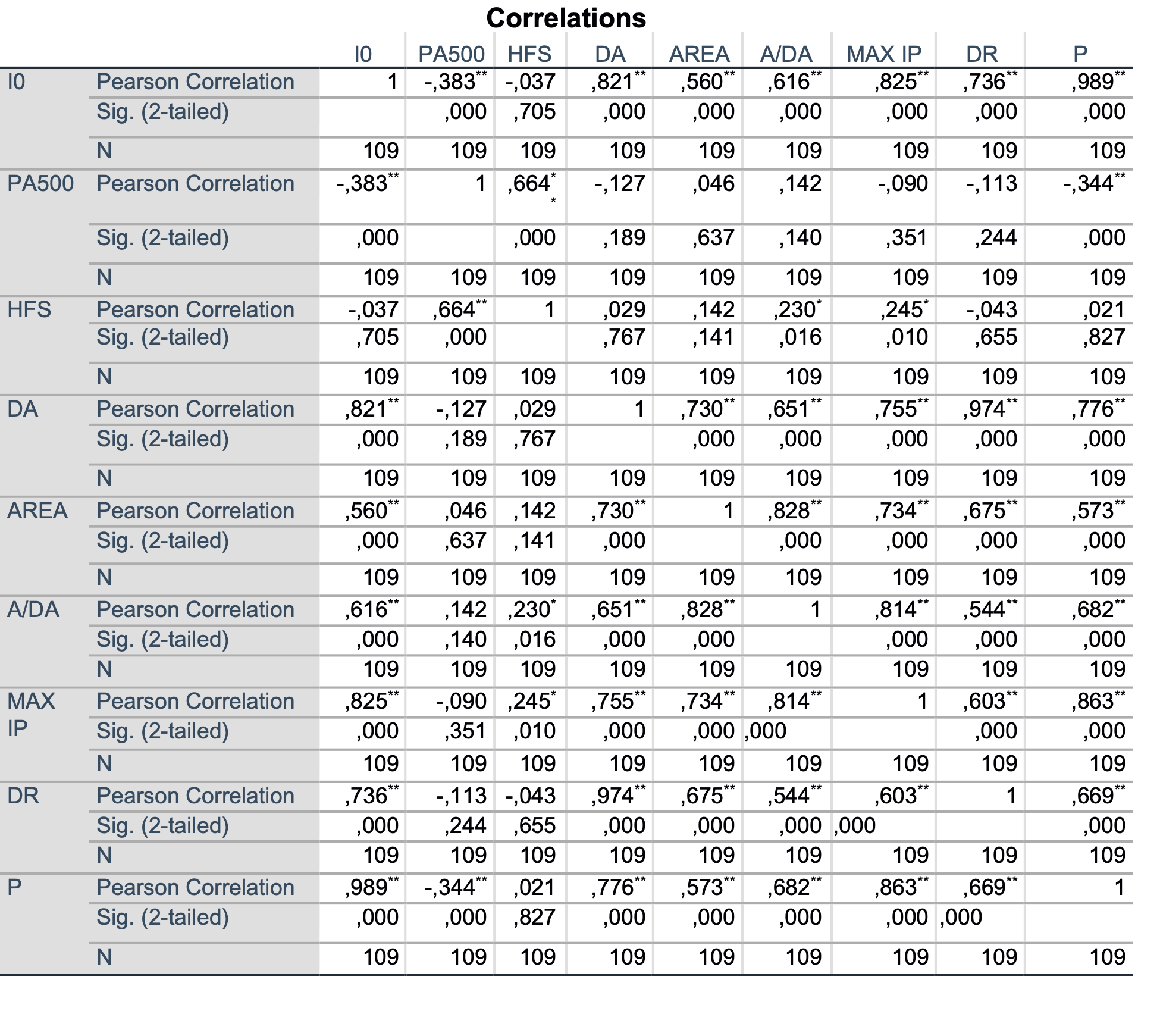
Ugotovimo lahko, da je spremenljivka I0 najbolj korelirana s spremenljivko P, saj je vrednost Pearsonovega koeficienta korelacije enaka 0.989 (popolna povezanost). Vrednost je pozitivna, kar pomeni, da če ena spremenljivka narašča, potem tudi druga narašča. V primeru negativnega korelacijskega koeficienta pomeni, da ko ena spremenljivka narašča, druga pada in obratno.
Po Pearsonovem koeficientu korelacije spremenljivka I0 dobro korelira z naslednjimi spremenljivkami: DA, MAX IP in DR (vrednost približno 0.75 ali več). Spremenljivka PA500 je najbolj korelirana s spremenljivko HFS (0.664). Vse omenjene korelacije so statistično značilne.
Pri izračunih koeficienta testiramo še ničto hipotezo: Vrednost korelacije je enaka nič.
V primeru, ko je p-vrednost večja od 0.05 ničto hipotezo sprejmemo, ko pa so p-vrednosti manjše od 0.05 lahko ugotovimo, da je korelacija med spremenljivkami statistično značilno različna od nič, kar pomeni, da sta spremenljivki povezani.
Poglejmo še tabelo Spearmanovih koeficientov korelacije:
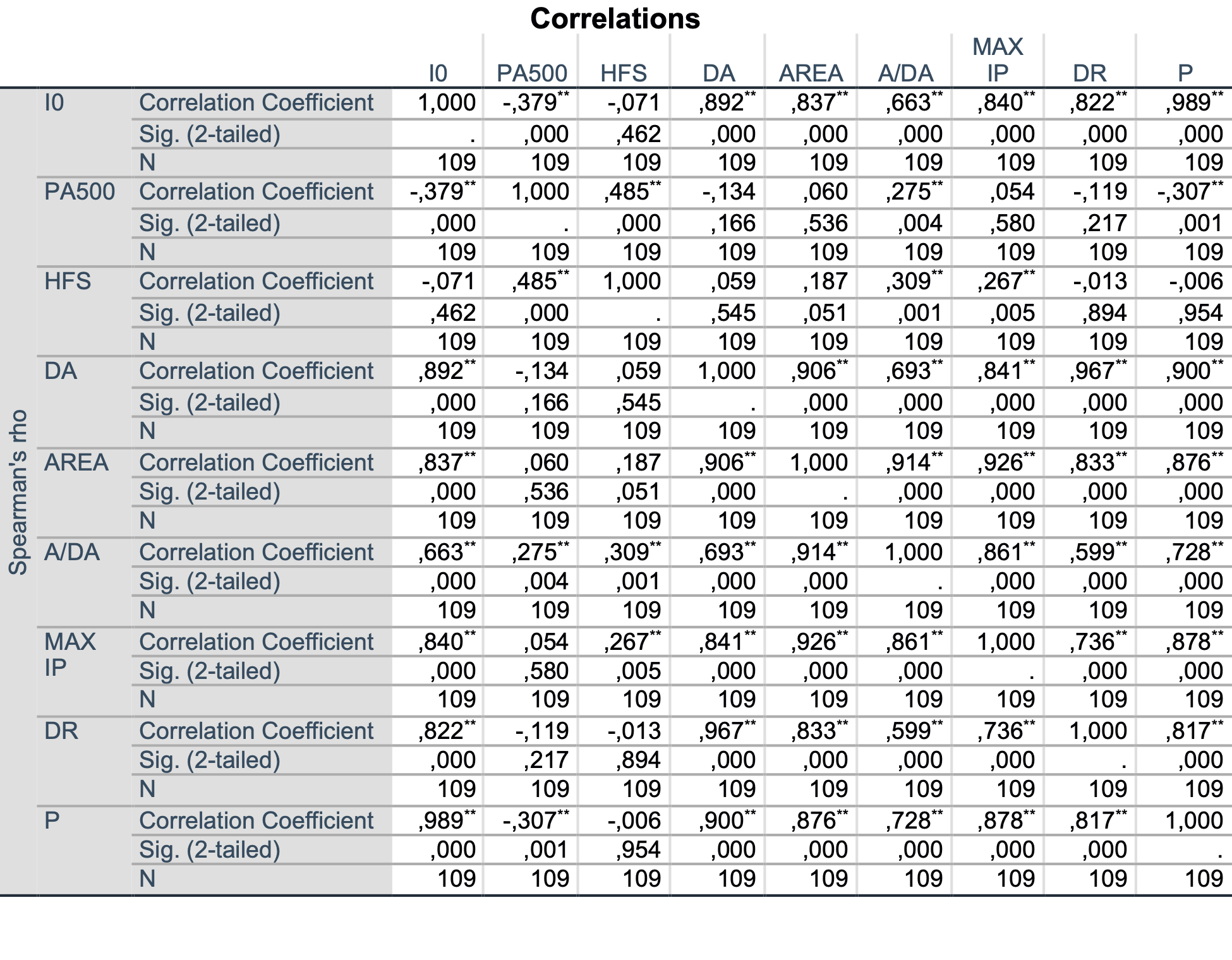
Če gledamo korelacije spremenljivke I0 v tej tabeli z ostalimi spremenljivkami, lahko ugotovimo, da je s spremenljivko I0 dobro povezana tudi spremenljivka AREA. Gre torej za nelinearno povezanost, v našem primeru predvsem zaradi tega, kar smo že opazili pri grafu medsebojne povezanosti, da imamo sicer linearno povezanost, vendar z eno močno odstopajočo točko, kar na Spearmanovo korelacijo, kjer primerjamo med sabo vrstni red meritev, ne vpliva.
6.2 Linearna regresija
Modelirali bomo težo novorojenčka FTW s spremenljivkami BPD, CP, AP in FL. Zanima nas, ali lahko iz teh parametrov izračunamo težo novorojenčka. Povezave med parametri bomo ugotavljali ločeno, torej povezavo med BPD in FTW, CP in FTW, AP in FTW ter FL in FTW.
Uvozimo podatke v SPSS program: File -> Import data -> Excel … in izberemo drugi list datoteke Foetal Weight.xlsx (Worksheet: Data). Popravimo podatke tako, da prvo vrstico v Data View, ki je brez vrednosti izbrišemo z desnim klikom na vrstico in izbiro Clear.
Najprej bomo težo novorojenčka FTW modelirali s spremenljivko BPD.
Narisali bomo graf medsebojnega raztrosa podatkov z ukazom Graphs -> Chart Builder…, s pomočjo katerega bomo ugotavljali povezavo med BPD in težo novorojenčka FTW.
Primerjali bomo spremenljivko BPD glede na spremenljivko FTW. Uporabili bomo graf medsebojnega raztrosa podatkov, ki ga kot Scatter/Dot najdemo v spodnjem levem okvirčku v zavihku Gallery. Izberemo prvi tip scatterplot-a in ga povlečemo v polje. Spremenljivko BPD prenesemo na x-os, spremenljivko FTW pa na y-os, kot prikazuje slika.
V izvedbenem oknu SPSS se izriše graf raztrosa podatkov prikazan spodaj.
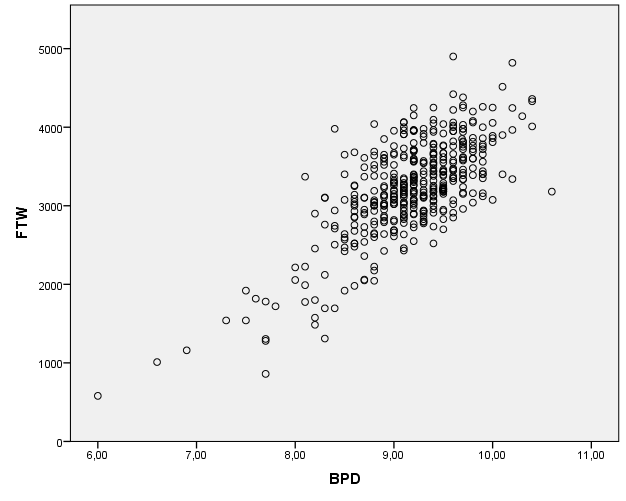
Ugotovimo, da večji kot je BPD, večji je tudi FTW. Meritve so na desni strani grafa bolj gosto narisane, ker je tam večje število meritev.
Sedaj bomo zgradili model linearne regresije, pri čemer bo FTW odzivna spremenljivka, BPD pa opisna spremenljivka. Izgradili bomo model: \[FTW\sim\beta_{0} + \beta_{1}BPD + \varepsilon .\] Model bomo izračunali po principu linearne regresije. Ko bomo poznali koeficiente \(\beta_{0}\) in \(\beta_{1}\), bomo lahko napovedovali težo novorojenčka FTW z BPD.
To storimo z ukazom Analyze -> Regression -> Linear…, kjer za odvisno spremenljivko izberemo FTW za opisno pa BPD.
Po pritisku gumba OK, se nam izvede linearna regresija z izbranimi podatki. Izpišejo se nam naslednje tabele.
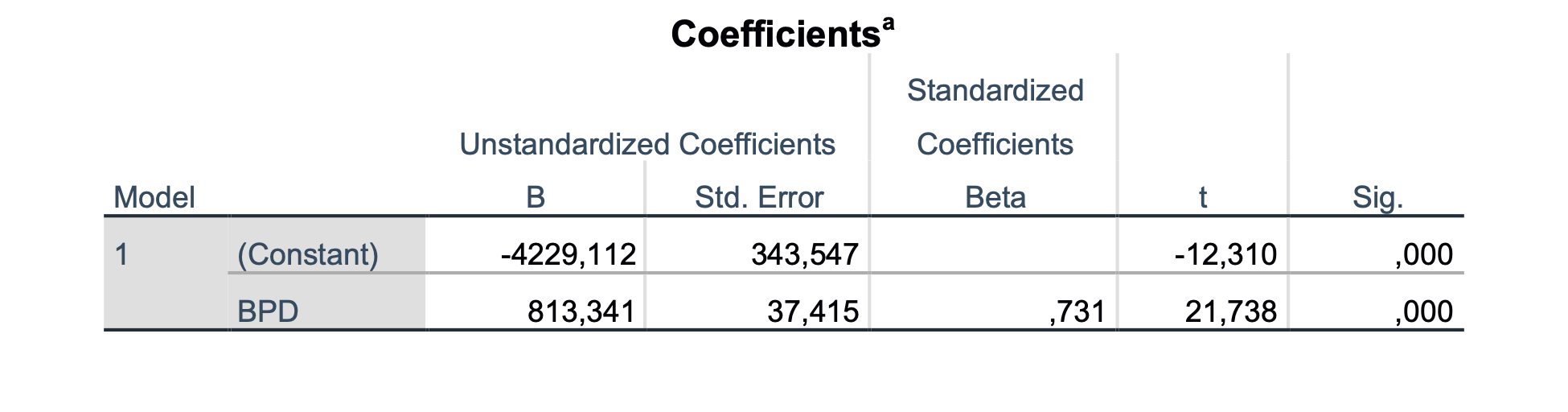
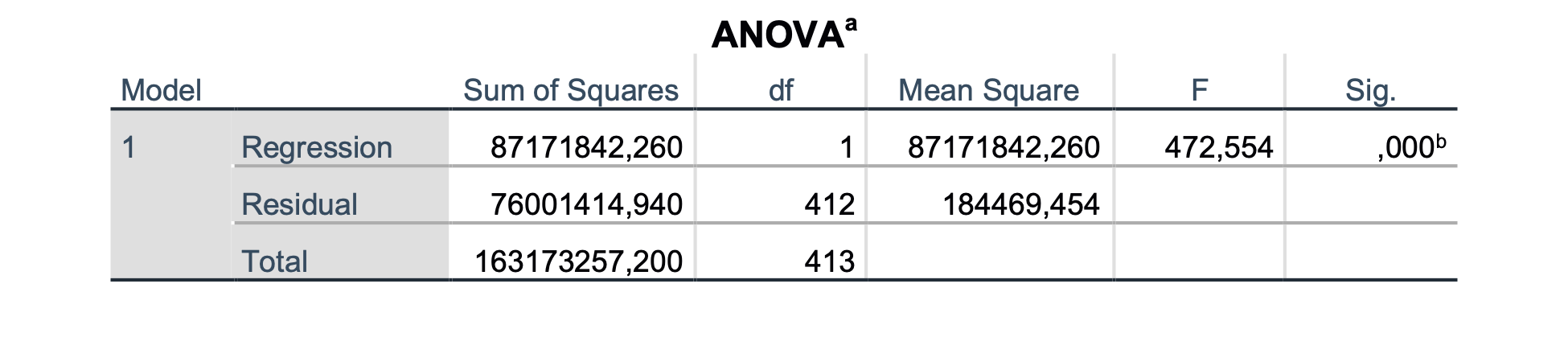

Iz tabele Coefficients lahko razberemo koeficiente β našega modela: β0 = −4229.1, β1 = 813.3 s p < 0.001, kar pomeni da je β1 statistično značilno različen od 0 oziroma, da je meritev BPD pomemben faktor za FTW. Iz tabele ANOVA ugotovimo, da je izračunani model statistično značilen, saj je p < 0.001.
Iz tabele Model Summary razberemo determinacijski koeficient R2 (Adjusted R Square), ki je v tem primeru 0.533. To pomeni, da naš model z BPD opiše 53.3 % variance FTW.
Za dodatno robustnost modela izračunamo še Cookovo razdaljo, ki pokaže, katere meritve pomembno vplivajo na izračun modela. Uporabimo ukaz Analyze -> Regression -> Linear… nato z gumbom Save… izberemo Cook’s.
V Data View se izpiše nova spremenljivka (COO_1) s Cookovimi razdaljami.
Narišemo graf raztrosa Cookove razdalje glede na BPD z ukazom Graphs -> Chart Builder… Spremenljivko BPD prenesemo na x-os, spremenljivko Cook’s distance pa na y-os, kot prikazuje slika.
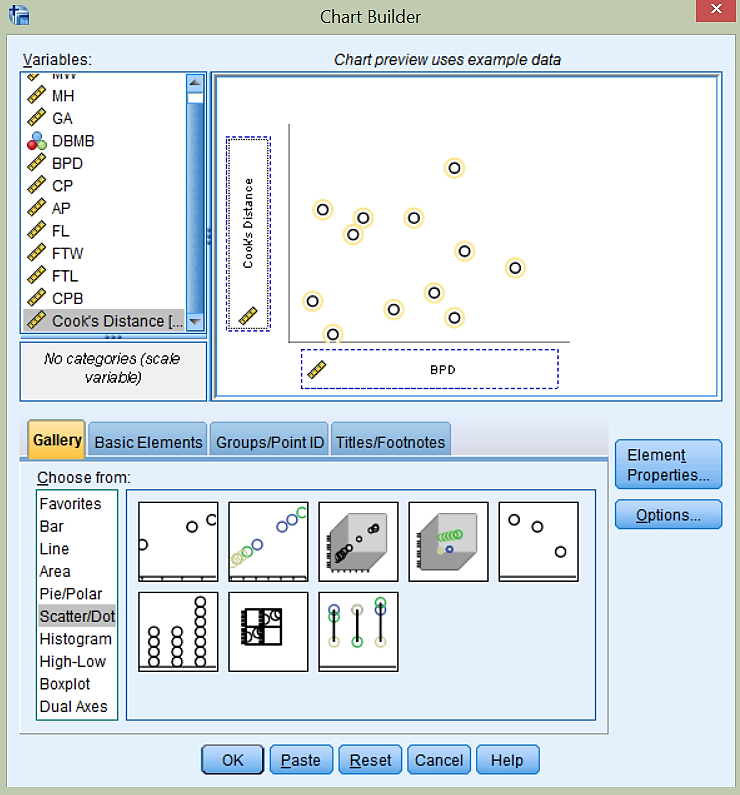
Izriše se naslednji graf.
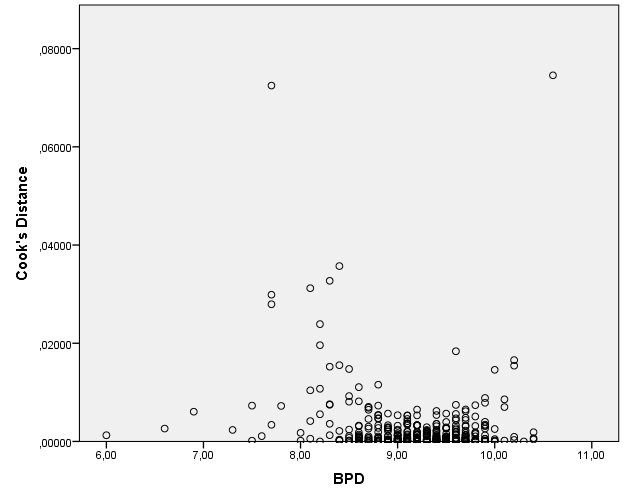
Iz grafa ugotovimo, da odstopata dve meritvi (meritvi, ki sta na grafu najvišje). Ti dve meritvi najbolj vplivata na kakovost modela, zato ju bomo izločili iz podatkov in ponovno izvedli izračun modela. Nov model bo bolj robusten, kar pomeni, da bo boljše napovedoval težo novorojenčka FTW v primeru pričakovanih meritev BPD, ne pa pri ekstremnih vrednostih BPD.
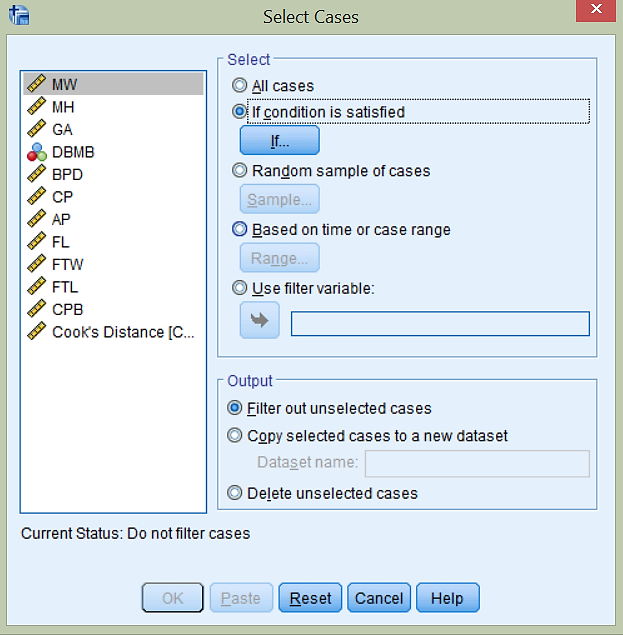
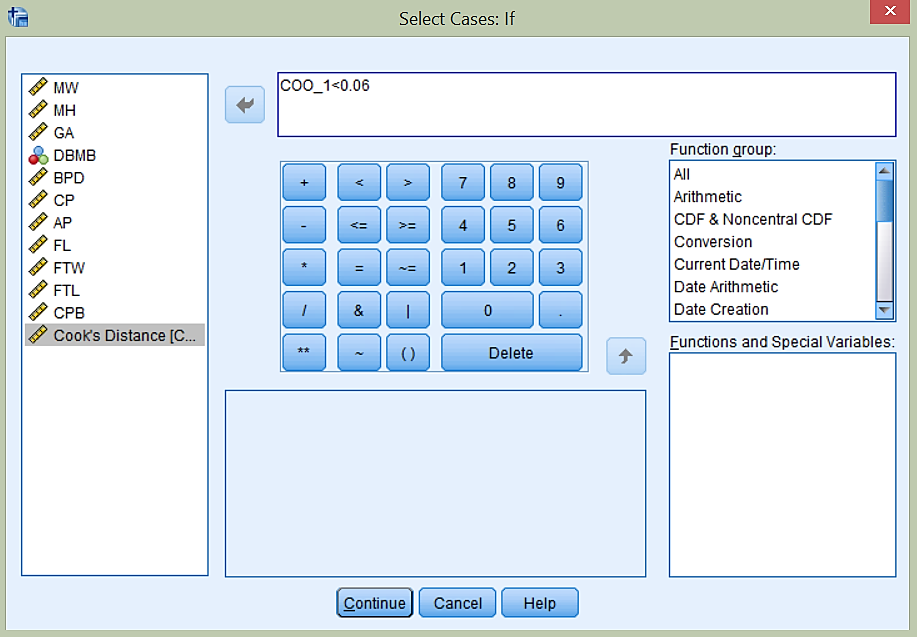
Cookova razdalja dveh odstopajočih meritev je glede na graf večja od 0.06. Meritvi bomo odstranili iz izračuna z ukazom Data -> Select Cases… in izbiro If condition is satisfied. S klikom na gumb If… se nam odpre novo okno: spremenljivko Cook’s distance povlečemo v okno na vrhu in določimo, da mora biti manjša od 0.06, kot prikazuje slika.
V Data View lahko vidimo, da 2. in 183. meritev ne bosta upoštevani v ponovni izračun modela.
Izračunajmo nov, popravljen model z ukazom Analyze -> Regression -> Linear…, kjer je FTW odzivna spremenljivka, BPD pa opisna spremenljivka.
Parametre iz SPSS tabel prepišemo v tabelo.
| \(β_1\) | p-vrednost koeficienta | p-vrednost modela | \(R^2\) | |
|---|---|---|---|---|
| BPD | 813.3 | < 0.001 | < 0.001 | 0.533 |
| Popravljen model z BPD | 813.5 | < 0.001 | < 0.001 | 0.535 |
Pri popravljenem modelu se rezultati spremenijo le malenkostno, saj imamo veliko število meritev in če odstranimo dve meritvi z malimi vrednostmi Cookove razdalje, modela ne spremenimo veliko.
Enak postopek linearne regresije ponovimo še za meritve CP, AP in FL posebej.
Rezultati modeliranja so v spodnji tabeli. Modeli niso popravljeni glede na Cookovo razdaljo.
| meritev | \(β_1\) | p-vrednost koeficienta | p-vrednost modela | \(R^2\) |
|---|---|---|---|---|
| CP | 252.2 | < 0.001 | < 0.001 | 0.549 |
| AP | 172.5 | < 0.001 | < 0.001 | 0.706 |
| FL | 893.5 | < 0.001 | < 0.001 | 0.558 |
Vsak parameter posamično je dober napovedovalec teže novorojenčka (\(β_1\) je statistično značilno različna od 0). Meritev AP je med njimi najboljša, saj ima najvišji determinacijski koeficient (70,6 %).
6.3 Multipla linearna regresija
Podatke pripravimo kot v začetnem koraku pri vaji iz pog. 6.2.
Dodatno lahko v Variable View zmanjšamo število decimalk na dve decimalni mesti. Slika prikazuje izsek zavihka Variable View.

Z izbranimi parametri (BPD, CP, AP, FL) bi radi napovedovali težo novorojenčka – FTW.
\[FTW\ \sim\ BPD + CP + AP + FL\]
Spremenljivko FTW želimo napovedati s spremenljivkami FL, AP, CP in BPD skupaj, zato izdelamo model multiple linearne regresije z ukazom Analyze -> Regression -> Linear… Kot odzivno spremenljivko izberemo FTW, kot opisne spremenljivke izberemo FL, AP, CP, BPD. Metoda modeliranja je Enter.
Model linearne regresije se izračuna po pritisku na gumb OK.
V izvedbenem oknu se nam izpišejo tabele regresijske analize:
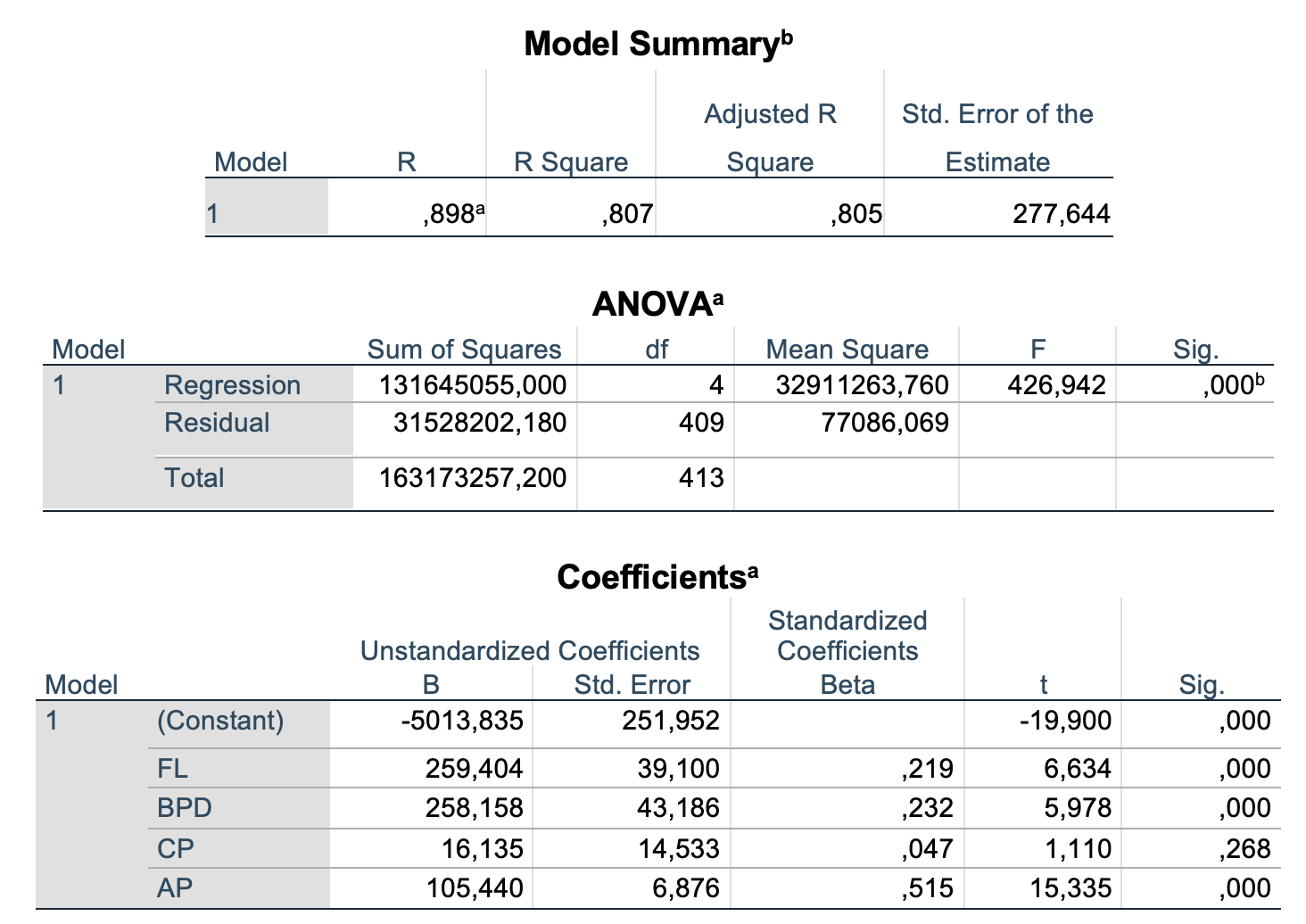
Tabela Model Summary nam pove, kakšen je determinacijski koeficient (R2) regresijskega modela. Tabela ANOVA nam pove, ali je regresijski model statistično značilen (p-vrednost regresijskega modela). V tabeli Coefficients so izračunani koeficienti β in pripadajoče p-vrednosti za posamezno spremenljivko.
Na podlagi teh rezultatov lahko sestavimo spodnjo tabelo:
| β | p-vrednost koeficienta | p-vrednost modela | R2 | |
|---|---|---|---|---|
| BPD | 258.2 | < 0.001 | < 0.001 | 0.805 |
| CP | 16.1 | 0.268 | ||
| AP | 105.4 | < 0.001 | ||
| FL | 259.4 | < 0.001 |
Rezultati nam kažejo, da je model s štirimi spremenljivkami (BPD, CP, AP in FL) statistično ustrezen (F = 426.9, p < 0.001). Determinacijski koeficient je enak 0.805, kar pomeni da z njim opišemo 80.5 % variance FTW. Vrednosti β koeficientov spremenljivk BPD, AP in FL so statistično značilno različne od nič (p < 0.001), β koeficient spremenljivke CP pa ni statistično značilno različen od nič (p = 0.268) in so s tem meritve CP statistično nepomembne za naš model.
Izračunali bomo še korelacije med parametri BPD, CP, AP in FL.
Izvedemo ukaz Analyze -> Correlate > Bivariate. Kot spremenljivke izberemo parametre BPD, CP, AP in FL ter izberemo izračun Pearsonovega korelacijskega koeficienta.
V izvedbenem oknu dobimo naslednjo tabelo:
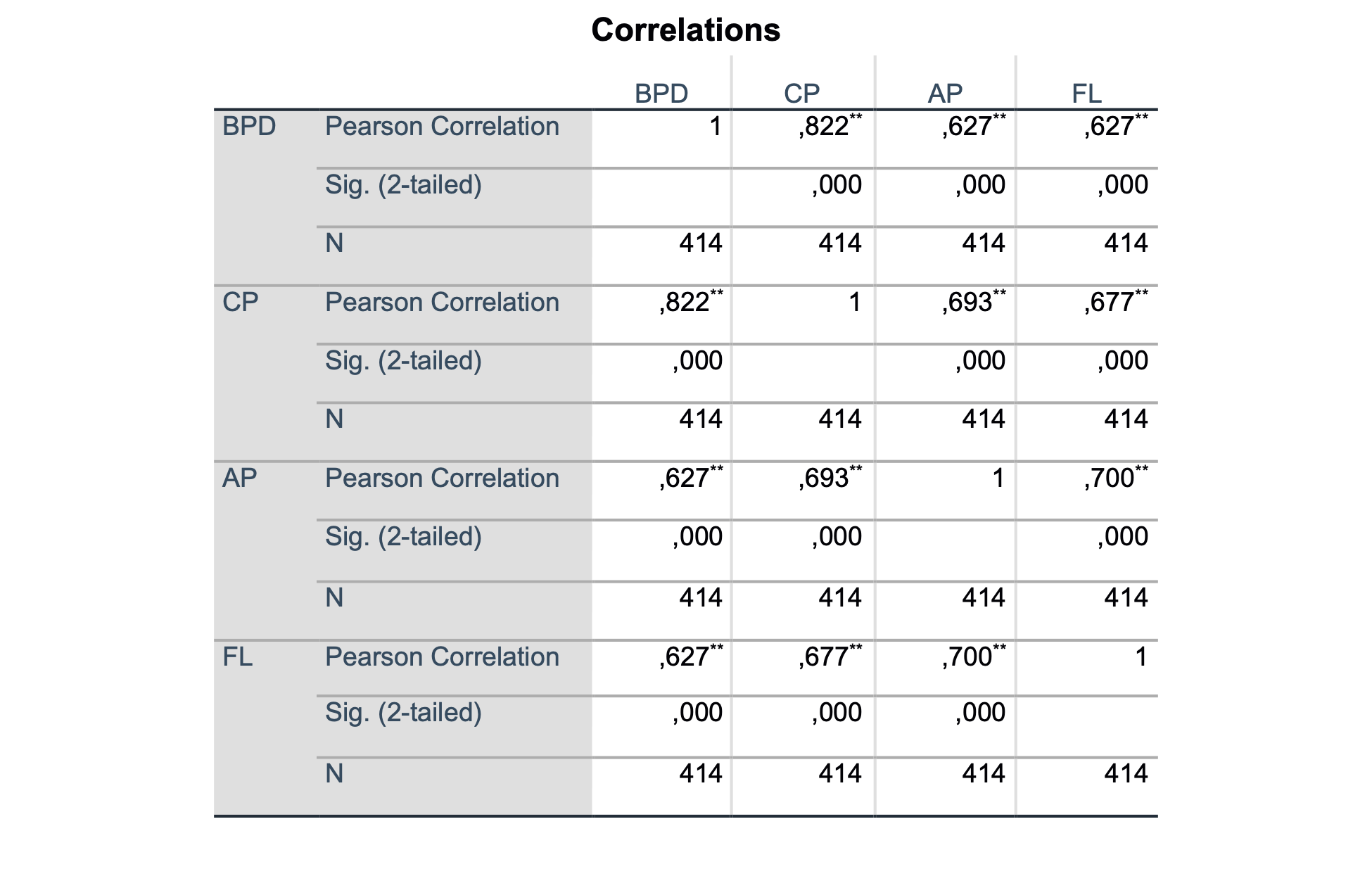
Ugotovimo, da je BPD močno koreliran s CP (0.82), kar pomeni, da ju lahko v modelu obravnavamo kot kofaktorja. To pomeni, da če eno spremenljivko vključimo v model, ni potrebno druge, saj spremenljivke, ki so med seboj korelirane, ne izboljšajo modela.
6.4 Multipla linearna regresija – koračna metoda
Podatke pripravimo kot v začetnem koraku pri vaji iz pog. 6.2.
Spremenljivko FTW želimo napovedati s spremenljivkami FL, AP, CP in BPD. Izdelamo model multiple linearne regresije po koračni metodi z ukazom Analyze -> Regression -> Linear… Kot odzivno spremenljivko izberemo FTW, kot opisne spremenljivke izberemo FL, AP, CP, BPD. Metoda modeliranja je Stepwise.
Model linearne regresije se izračuna po pritisku na gumb OK.
V izvedbenem oknu se nam izračunajo tabele regresijske analize:
Koračna metoda modelira regresijski model tako, da v vsakem koraku v model vstavi po eno spremenljivko in sicer tako, da na vsakem koraku izbere tisto spremenljivko, kjer ima regresijski koeficient najmanjšo p-vrednost (vendar manjšo od 0.05), nato izračuna nov model, po potrebi odstrani spremenljivke s p-vrednostmi nad mejno vrednostjo (običajno p > 0.10) in doda novo spremenljivko z najmanjšo p-vrednostjo (p < 0.05). Gradnja modela se konča, ko ne moremo več dodajati spremenljivk, bodisi ker jih ni več, ali pa imajo vse p-vrednosti višje od 0.05.
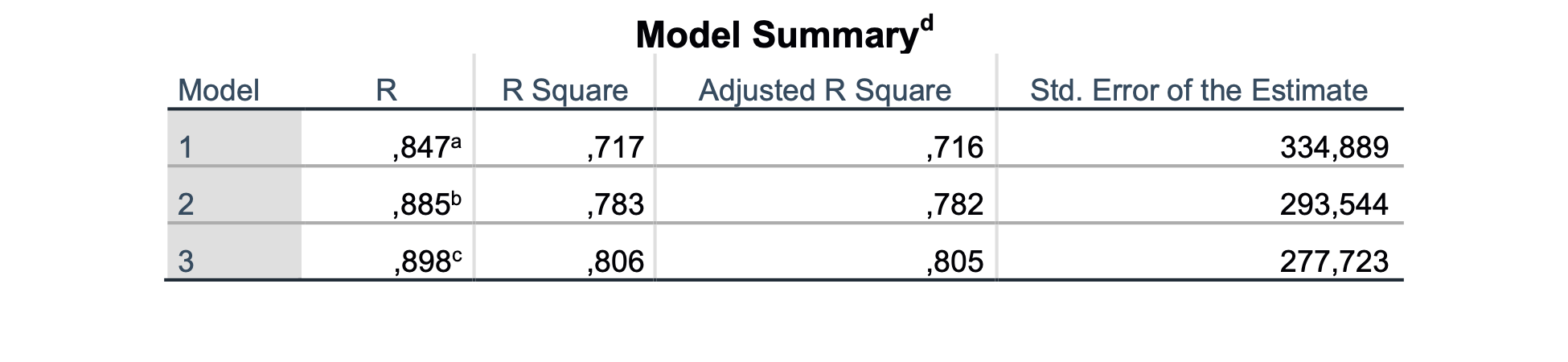
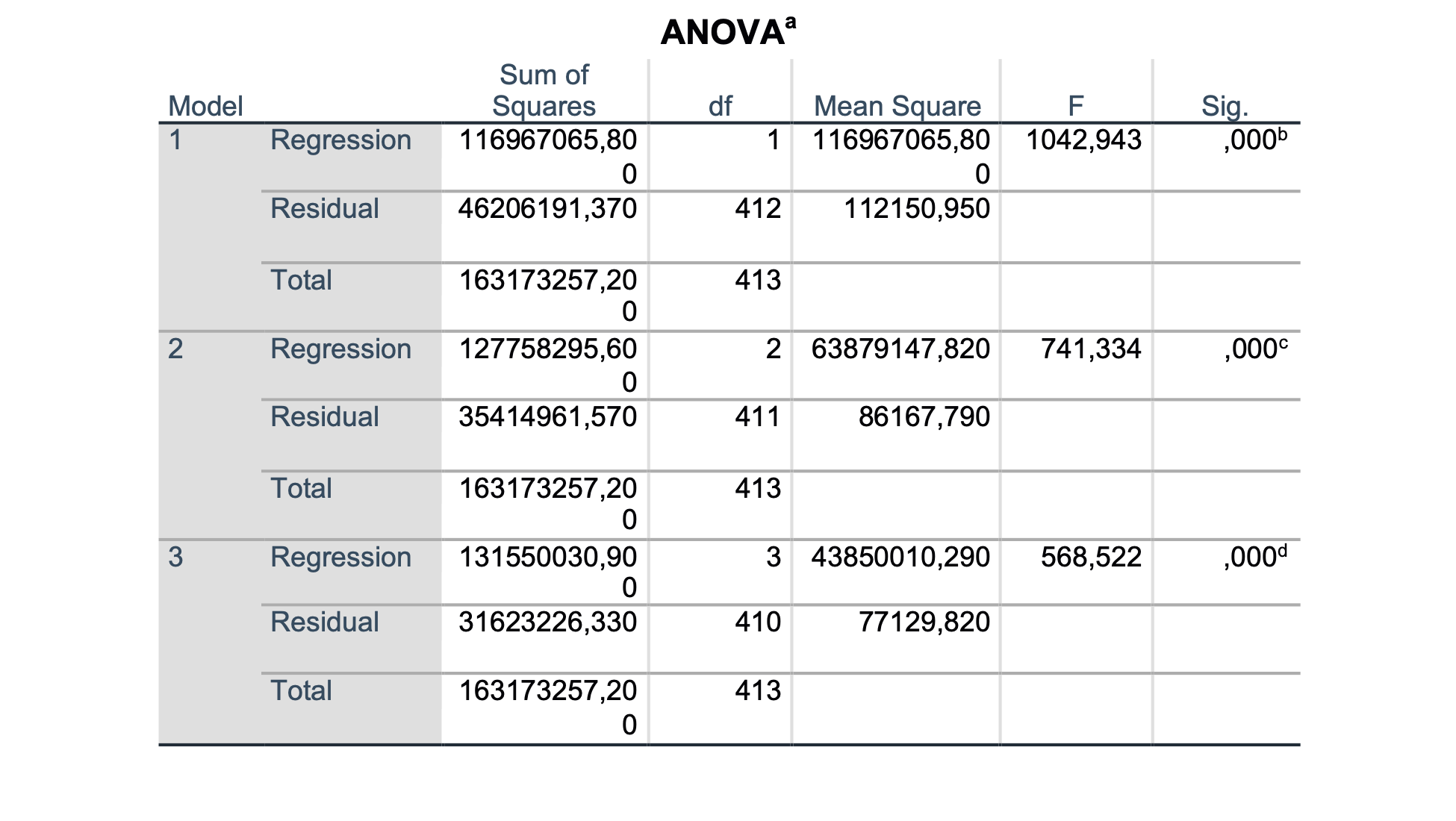
V našem primeru je SPSS najprej vključil v model spremenljivko AP, potem še BPD in na koncu FL, spremenljivka CP ni vključena v model, saj ima regresijski koeficient p-vrednost > 0.05.
Tabela Model Summary nam pove kakšen je determinacijski koeficient regresijskega modela. Tabela ANOVA nam pove, ali je regresijski model statistično ustrezen (p-vrednost regresijskega modela). V tabeli Coefficients so izračunani regresijski koeficienti β in pripadajoče p-vrednosti za posamezno spremenljivko.
Izrišimo si tabelo:
| Št. modela | β | p -vrednost koeficienta |
p -vrednost modela |
R2 | |
|---|---|---|---|---|---|
| 1 | AP | 173.4 | < 0.001 | < 0.001 | 0.716 |
| 2 | AP | 131.0 | < 0.001 | < 0.001 | 0.782 |
| BPD | 367.2 | < 0.001 | |||
| 3 | AP | 107.5 | < 0.001 | < 0.001 | 0.805 |
| BPD | 289.1 | < 0.001 | |||
| FL | 268.3 | < 0.001 |
Rezultati nam kažejo, da je prvi regresijski model s spremenljivko AP statistično značilno ustrezen (p < 0.001). Determinacijski koeficient je enak 0.716, kar pomeni da z njim opišemo 71.6 % variance. Vrednost regresijskega koeficienta parametra AP je statistično značilno različna od nič (p < 0.001).
Drugi regresijski model vsebuje spremenljivki AP in BPD in je statistično ustrezen (p < 0.001). Determinacijski koeficient je enak 0.782, kar pomeni, da s tem modelom opišemo več variance kot s prvim (78.2 %). Vrednosti regresijskih koeficientov parametra AP in BPD sta statistično značilno različni od nič (p < 0.001).
Tretji regresijski model vsebuje spremenljivke AP, BPD in FL in je statistično ustrezen (p < 0.001). Determinacijski koeficient je enak 0.805, kar pomeni, da s tem modelom opišemo največ variance v primerjavi s prejšnjima modeloma (80.5 %). Vrednosti regresijskih koeficientov parametra AP, BPD in FL so statistično značilno različne od nič (p < 0.001).
Končni model ne vsebuje spremenljivke CP, ki ni statistično pomembna za napovedovanje FTW, kar smo pokazali že v prejšnji nalogi, ko smo ugotovili, da sta spremenljivki BPD in CP kofaktorja.
6.5 Multipla linearna regresija – dodajanje nelinearnih členov – minimizacija modela s koračno metodo
Podatke pripravimo kot v začetnem koraku pri vaji pog. 6.3.
Ker bomo dodajali tudi člene višjega reda v regresijski model, najprej narišemo grafe raztrosa spremenljivk BPD, CP, AP in FL s spremenljivko FTW, da ugotovimo, ali obstajajo tudi kakšne nelinearne povezave med opazovanimi spremenljivkami in spremenljivko FTW.
Izvedemo ukaz Graphs- > Graphboard Template Chooser … in izberemo spremenljivke BPD, CP, AP, FL, FTW. Izrišemo Scatterplot Matrix (SPLOM):
Iz matrike grafov raztrosa se osredotočimo samo na zadnjo vrsto grafov, ki prikazujejo grafe spremenljivke FTW v odvisnosti od spremenljivk BPD, CP, AP in FL.
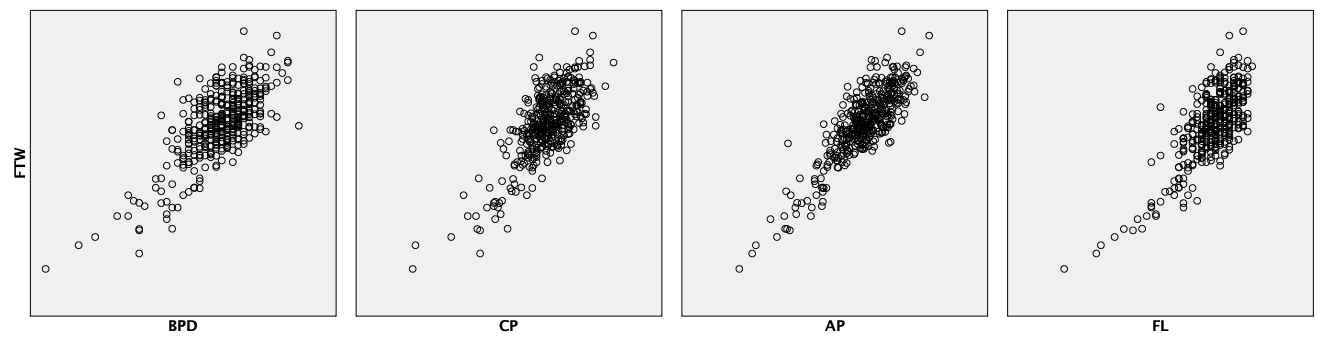
Ugotovimo lahko, da so bile premice v prejšnjih vajah kar ustrezni modeli za modeliranje FTW, vendar lahko pri spremenljivkama CP in FL opazimo nelinearno (kvadratno) odvisnost s FTW.
Zato se odločimo, da bomo FTW modelirali tako, da bomo v linearni model dodajali še nelinearne člene, sestavljene iz osnovnih meritev:
\[FTW\sim BPD + CP + AP + FL + \] \[ {BPD}^{2} + {CP}^{2} + {AP}^{2} + {FL}^{2} + \] \[BPD \cdot \ CP + BPD \cdot AP + BPD \cdot FL + CP \cdot AP + CP \cdot FL + AP \cdot FL\]
Zgradili bomo torej model multiple linearne regresije s 14 spremenljivkami, pri čemer bomo uporabili koračno metodo. Tako bomo dobili model z najmanjšim številom regresijskih členov.
Ustvariti moramo 10 novih spremenljivk. Nove spremenljivke bomo ustvarjali z ukazom Transform -> Compute Variable…
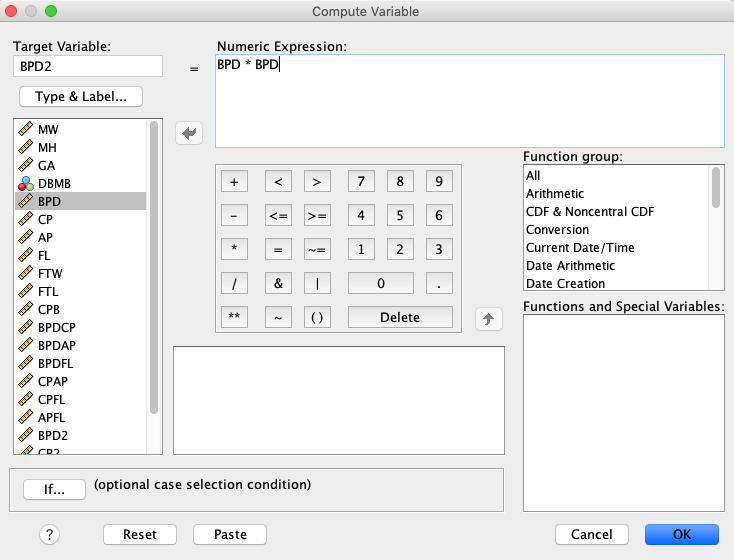
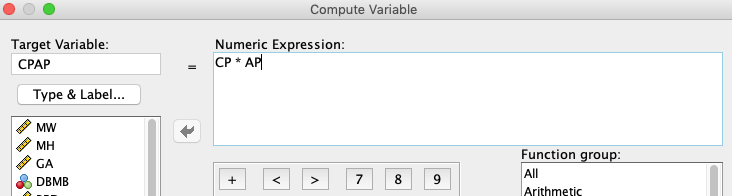
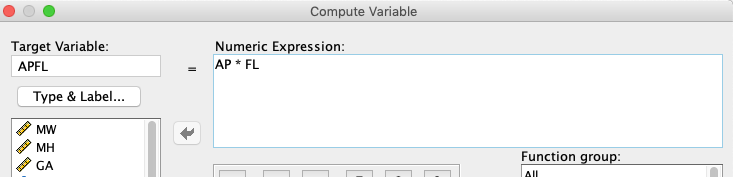
Definiramo nove spremenljivke BPD2=BPD*BPD, BPDCP=BPD*CP, BPDAP=BPD*AP, BPDFL=BPD*FL, CP2=CP*CP, CPAP=CP*AP, CPFL=CP*FL, AP2=AP*AP, APFL=AP*FL in FL2=FL*FL. Nekateri izračuni novih spremenljivk so prikazani spodaj.
V podatkovnem oknu dobimo nove spremenljivke:
S tem smo dodali nelinearne člene, izvajali pa bomo linearno regresijo z ukazom Analyze -> Regression -> Linear…
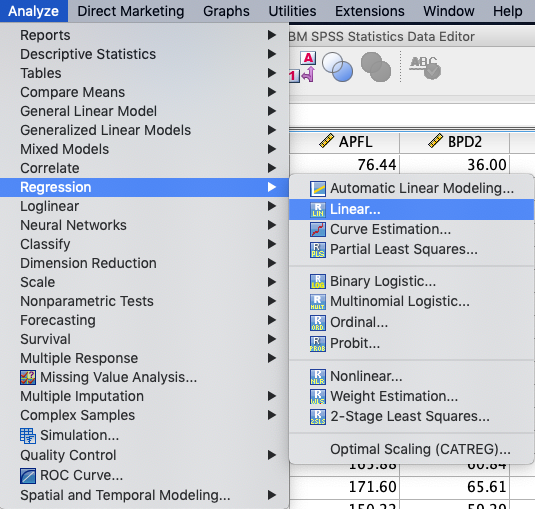
Za odzivno spremenljivko izberemo FTW, za Block 1 pa vnesemo vseh 14 spremenljivk s katerimi modeliramo FTW. Za metodo izberemo Stepwise (koračno) metodo.
Dodatno še izračunamo napake z gumbom Save …, kjer označimo Residuals: Standardized, in Cookovo razdaljo, kjer označimo Distances: Cook’s.
V SPSS se izračuna več tabel. Zanimajo nas tri tabele:
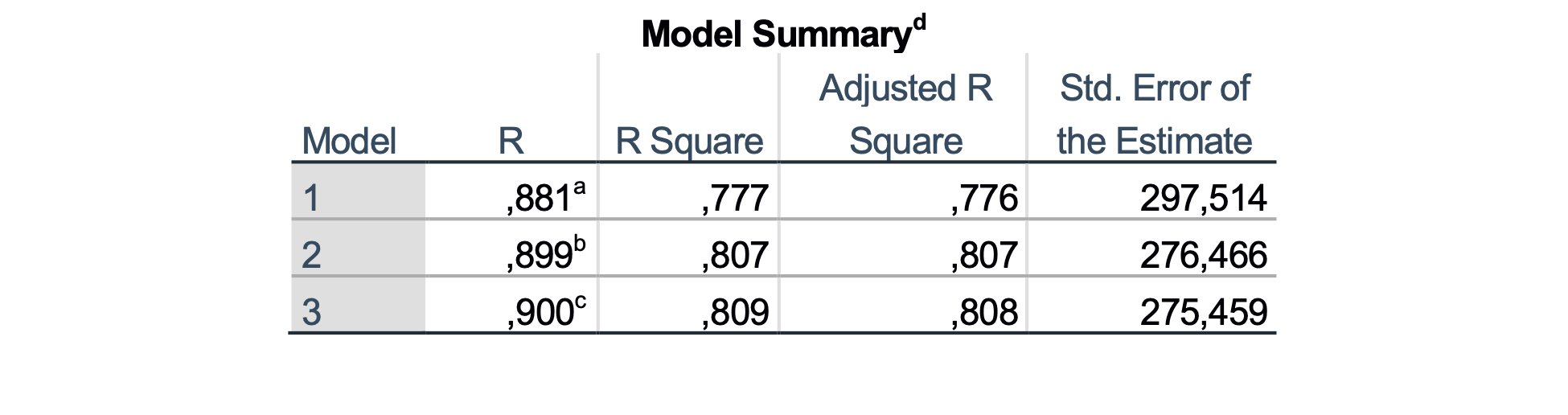
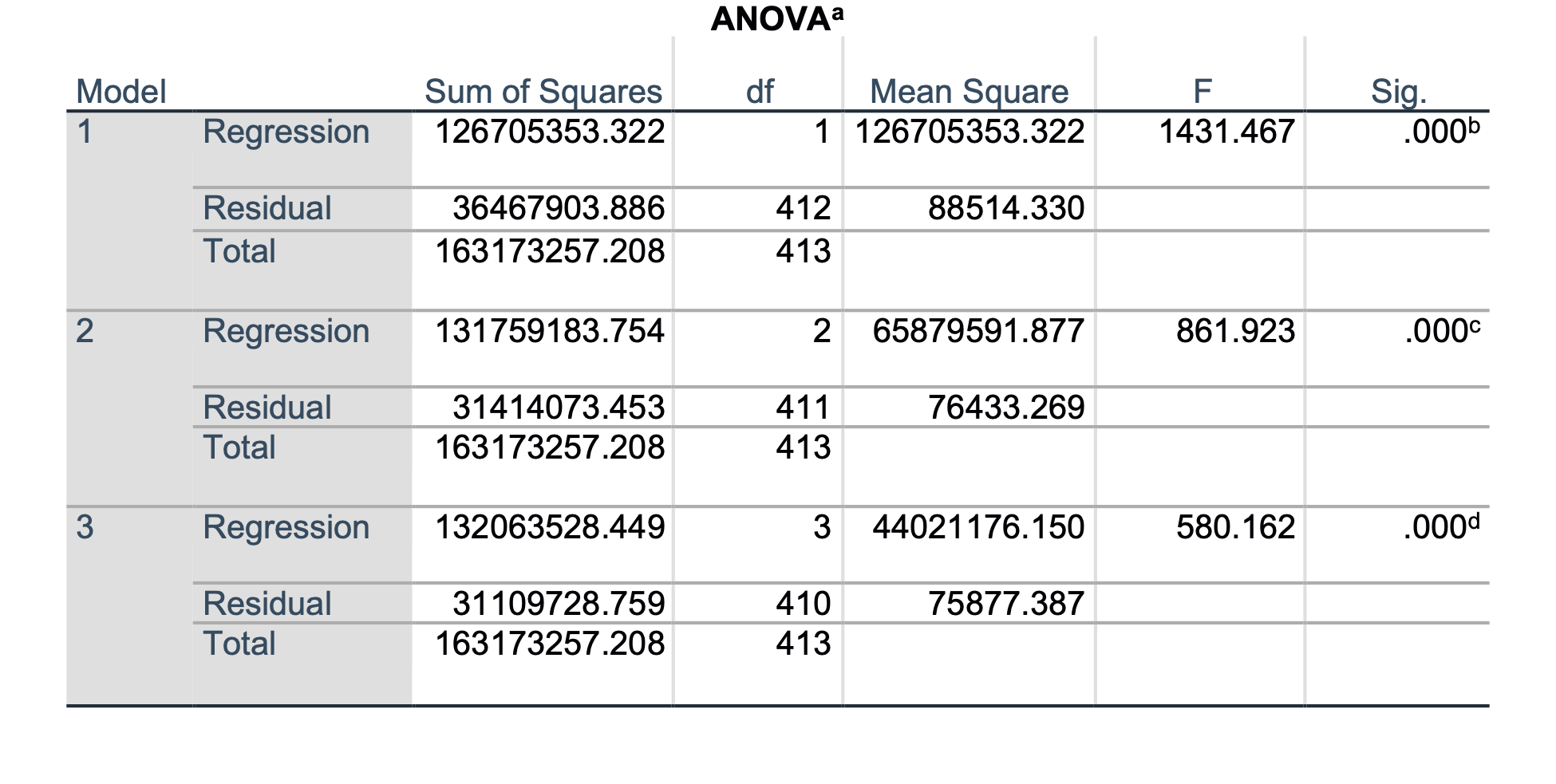
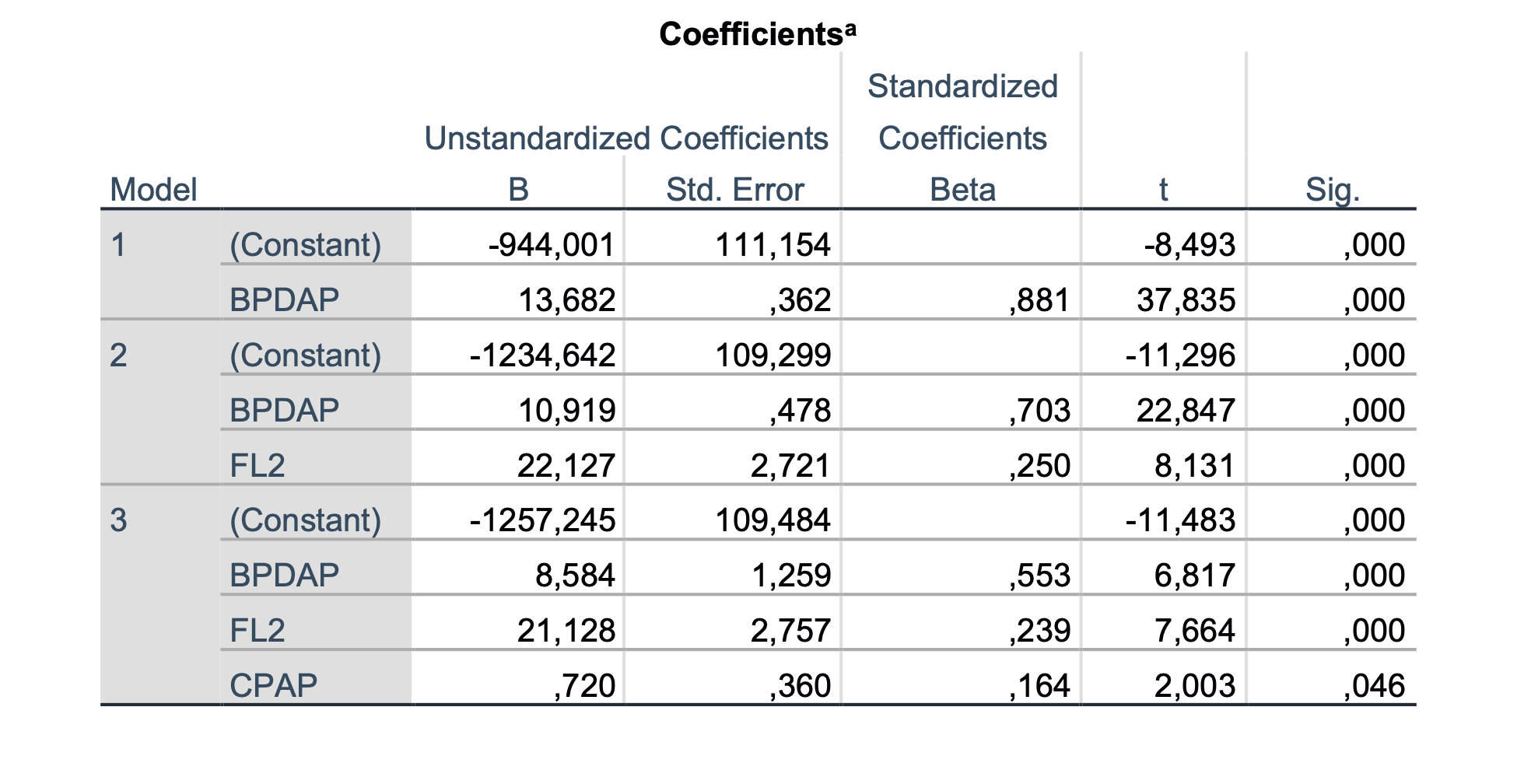
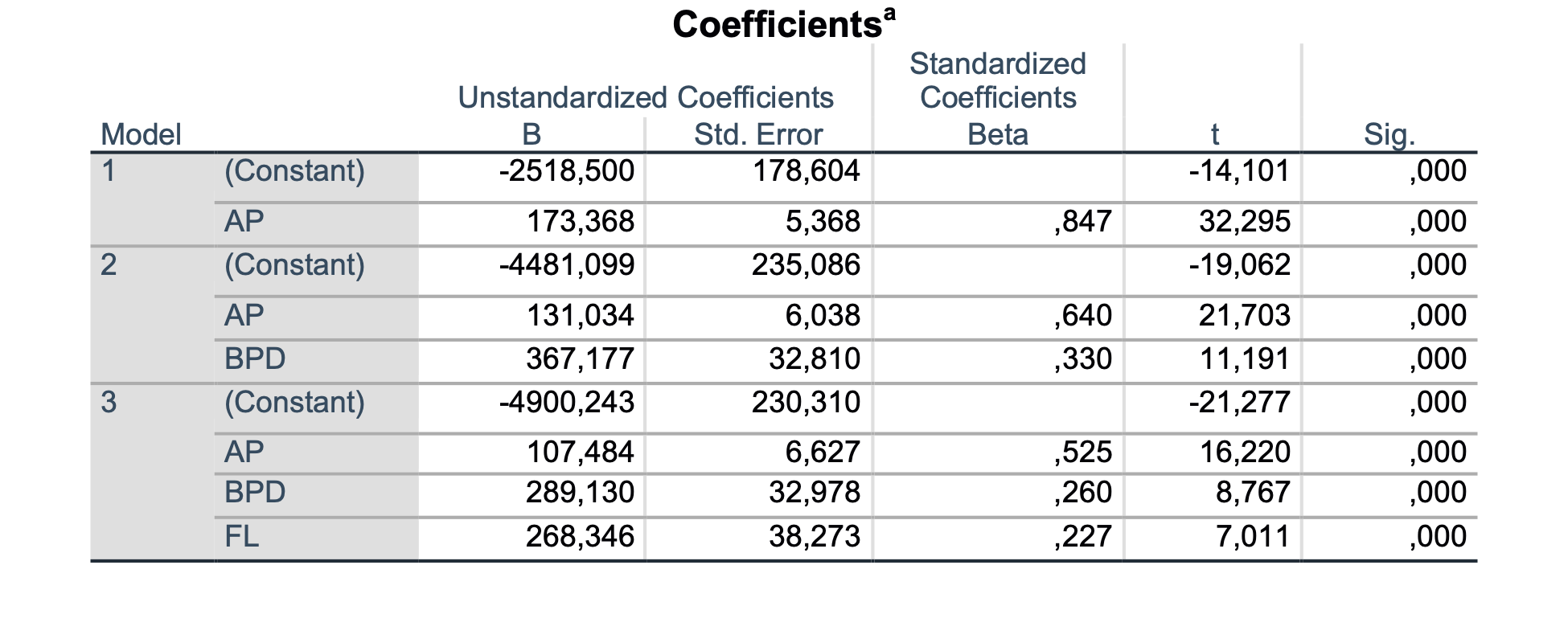
Po koračni metodi smo zgradili tri modele: v prvem modelu je vključena spremenljivka BPD*AP, v drugemu modelu se je spremenljivki BPD*AP dodala spremenljivka FL2, tretji model pa vsebuje še spremenljivko CP*AP. Zanima nas zadnji model, ki hkrati predstavlja tudi minimalni regresijski model za napovedovanje FTW. Podatki so prikazani v spodnji tabeli:
| β | p-vrednost koeficienta | p-vrednost modela | R2 | |
|---|---|---|---|---|
| BPD*AP | 8.6 | <0.001 | <0.001 | 0.808 |
| FL2 | 21.1 | <0.001 | ||
| CP*AP | 0.7 | 0.046 |
Iz podatkov lahko razberemo, da so v model vključene tri spremenljivke, ki so nelinearne kombinacije osnovnih spremenljivk BPD, AP, FL in CP (torej vseh). Ugotovimo lahko, da so regresijski koeficienti statistično značilno od nič različni, spremenljivka CP*AP je mejna, saj je p = 0.046. Model je prav tako statistično ustrezen in kakovosten, saj opiše 80.8 % skupne variance FTW. Glede na to, da je p-vrednost koeficienta pri spremenljivki CP*AP enaka 0.046, kar je blizu 0.05, bi jo lahko izločili iz modela, vendar jo ne bomo.
V nadaljevanju naredimo še analizo kakovosti dobljenega modela z analizo napak (residualov) in Cookovo razdaljo.
Narišimo graf kvartil-kvartil za prikaz normalnosti porazdelitve residualov modela in graf za prikaz heteroskedastičnosti residualov.
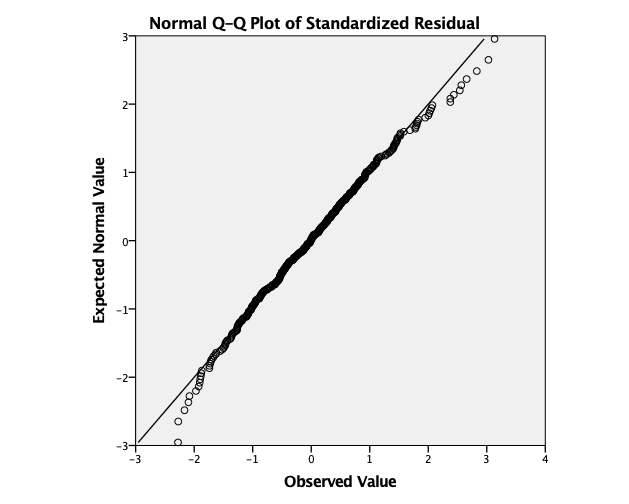
Kvartil-kvartil graf izvedemo z ukazom: Analyze -> Descriptive Statistics -> Q-Q Plots …, kjer izberemo spremenljivko Standardized Residual:
V izvedbenem oknu se nam izriše graf kvartil-kvartil, kjer lahko ugotovimo, da so residuali dobro razporejeni okoli premice v srednjem delu, na obeh koncih pa ne, vendar kljub temu lahko trdimo, da so napake normalno porazdeljene.
Naslednji graf, ki ga rišemo, je graf napak v odvisnosti od spremenljivke FTW, da ugotovimo heteroskedastičnost napak. To izvedemo z izrisom grafa raztrosa (scatter plot) z ukazom: Graphs->Chart Builder… izberemo Scatter Plot in za x os izberemo FTW za y-os pa Standardized Residual:
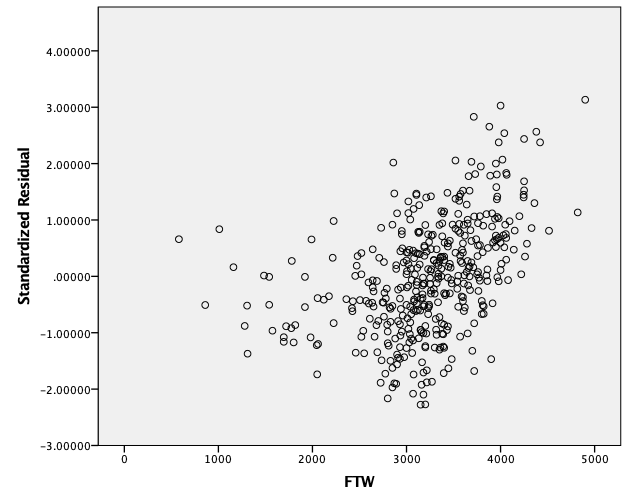
Dobimo graf raztrosa napak v odvisnosti od spremenljivke FTW, kjer lahko ugotovimo enakomeren raztros okoli vrednosti 0.0, mogoče v drugem delu malo bolj navzgor, v srednjem delu pa navzdol, nekega tipičnega vzorca pa ne prepoznamo. Zato lahko govorimo o enakomernem raztrosu residualov okoli 0.0, kar je v redu:
Izrišimo še meritve glede na Cookovo razdaljo tako, da ponovimo postopek kot prej, samo na y-os damo spremenljivko Cook’s distance:
Dobimo graf, ki je prikazan spodaj:
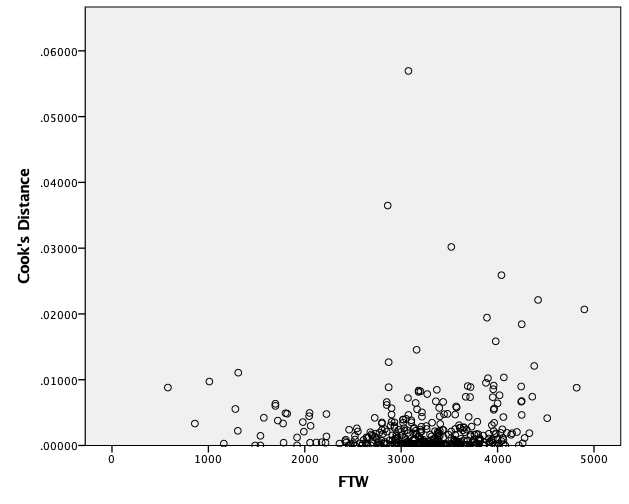
Lahko ugotovimo, da imamo eno točko, ki izrazito odstopa od ostalih. To je točka z največjo Cookovo razdaljo oziroma točka, ki najbolj vpliva na izračun regresijskega modela. Zato bomo ponovili modeliranje z odstranitvijo te točke. To naredimo z ukazom Data->Select Cases …, kjer izberemo v polju If condition is satisfied z gumbom If spremenljivko COO_1 < 0.05:
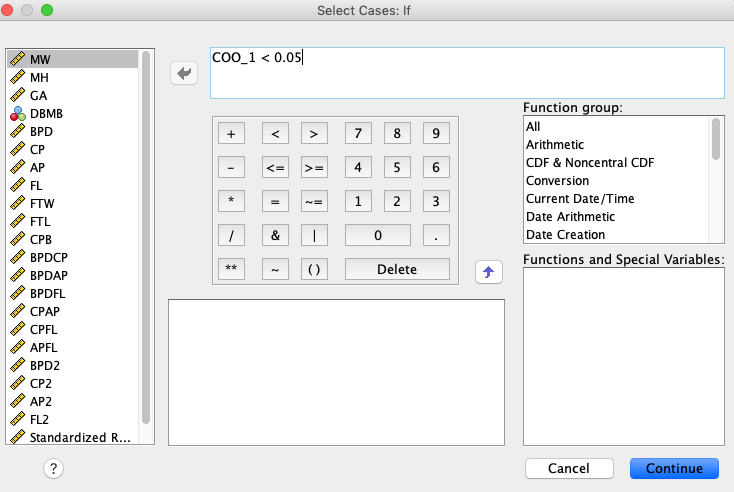
Tako smo izbrali vse točke, ki imajo Cookovo razdaljo manjšo od 0.05, torej vse razen najbolj odstopajoče točke.
Ponovimo modeliranje z linearnim regresijskim modelom: Analyze -> Regression -> Linear …. Za odzivno spremenljivko izberemo FTW, za Block 1 pa vnesemo vseh 14 spremenljivk. Za metodo izberemo Stepwise.
V izvedbenem oknu se izpišejo tabele, ki nas zanimajo:
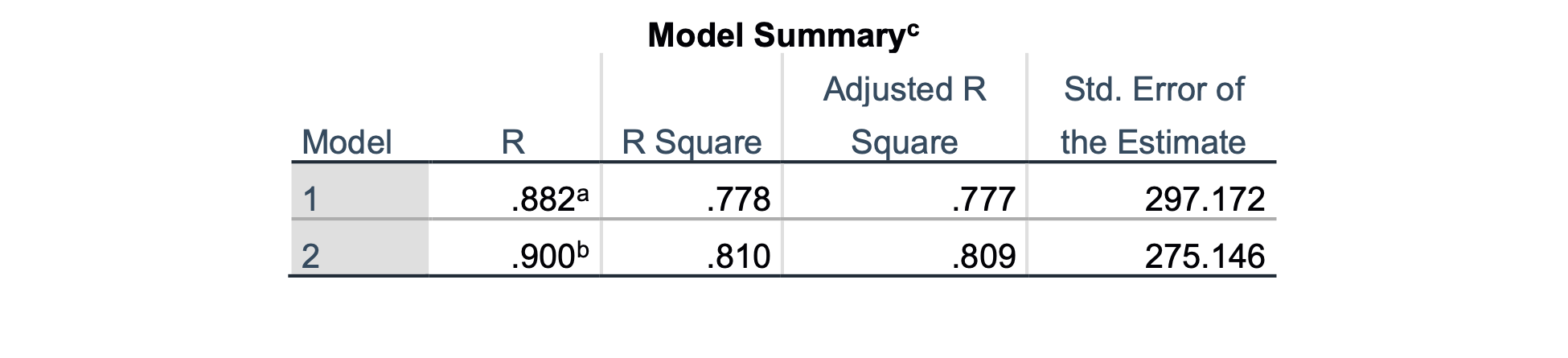
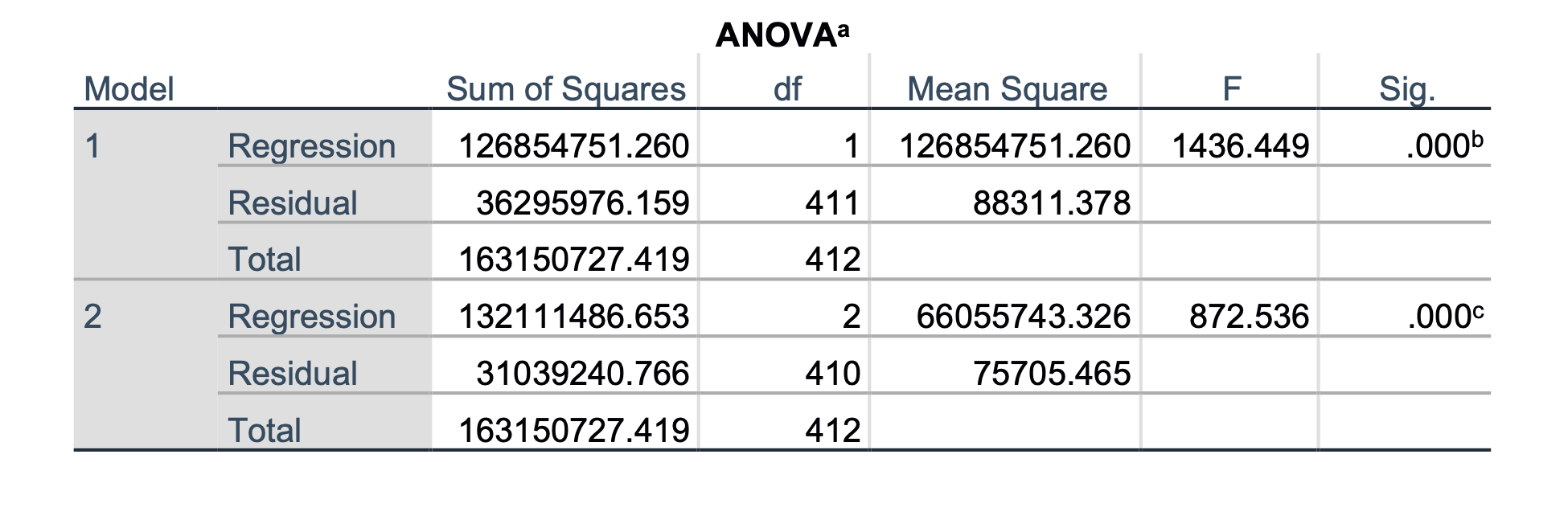
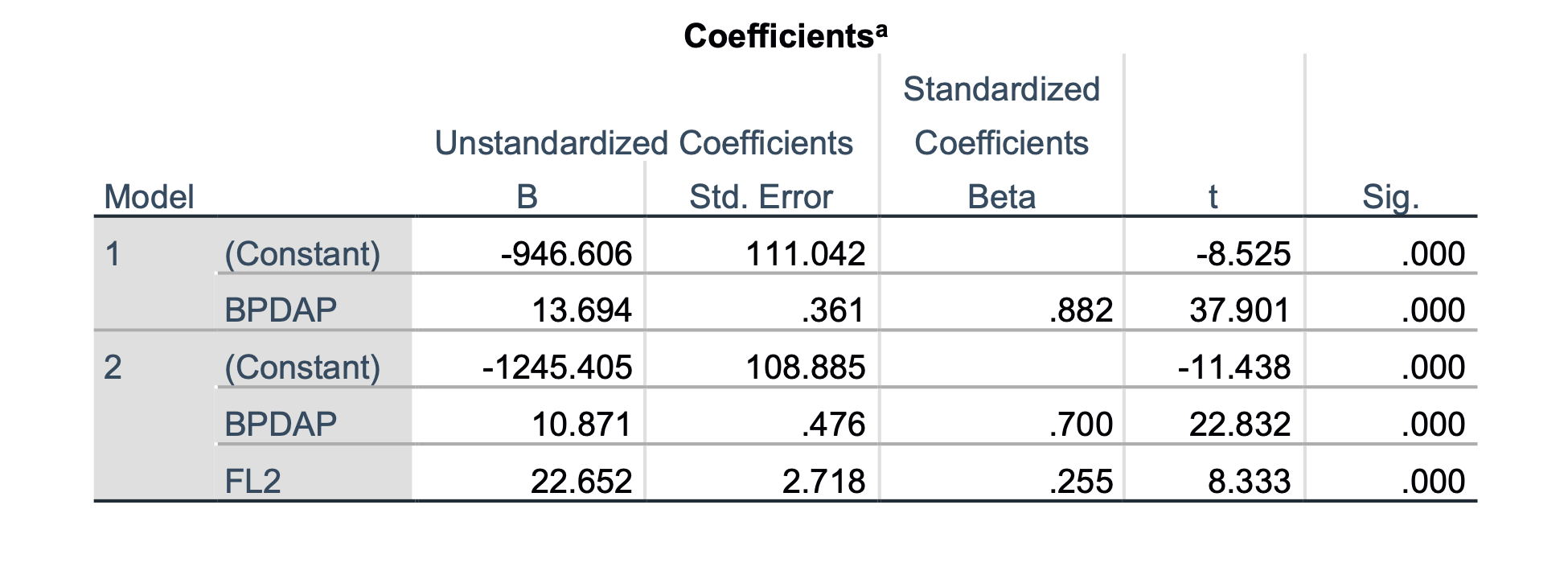
Iz tabel lahko ugotovimo, da smo v tem primeru po koračni metodi dobili samo dva modela, prvi model s spremenljivko BPD*AP in drugi s spremenljivkama BPD*AP in FL2. Zanima nas zadnji model, ki ga izpišemo v spodnji tabeli:
| β | p-vrednost koeficienta | p-vrednost modela | R2 | |
|---|---|---|---|---|
| BPD*AP | 10.9 | < 0.001 | < 0.001 | 0.809 |
| FL2 | 22.7 | < 0.001 |
Ugotovimo lahko, da je ta model malce boljši po determinacijskem koeficientu od prejšnjega modela, predvsem pa ne vključuje več spremenljivke CP*AP, ki je bila že prej mejna spremenljivka. To je končni – minimalni – model linearne regresije za modeliranje FTW s parametri BPD, FL, CP in AP.
6.6 Logistična regresija
V Excel datoteki titanic3.xls imamo zbrane podatke o potnikih Titanika. Vsaka vrstica v Excelu predstavlja enega potnika. Zanimajo nas naslednje spremenljivke (podatki o potnikih): age (starost), sex (spol), pclass (potovalni razred), parch in sibsp (ali so potovali sami ali z družino). Uvozimo podatke v SPSS program: File -> Import data -> Excel … in izberemo željeno datoteko.
Zanima nas, koliko ljudi je preživelo glede na spol in na razred v katerem so potovali. Spremenljivka survived je kategorijska spremenljivka z dvema kategorijama (0 = oseba je umrla, 1 = oseba je preživela). Spremenljivki sex in pclass sta obe kategorijski spremenljivki. Prva ima dve kategoriji (ženska, moški), druga pa tri (1 = prvi potovalni razred, 2 = drugi potovalni razred, 3 = tretji potovalni razred). Ker ugotavljamo povezave med kategorijskimi spremenljivkami, bomo uporabili kontingenčne tabele. Izvedemo opisno statistiko preživelih ali umrlih glede na spremenljivke: sex in pclass.
Analyze -> Desriptive Statistics -> Crosstabs.
Okno Crosstabs izpolnimo na naslednji način:
V zavihku Statistics… izberemo test hi-kvadrat. V izvedbenem oknu se nam izrišejo kontingenčne tabele in tabele hi-kvadrat testa. Najprej poglejmo rezultate za spremenljivko spol:
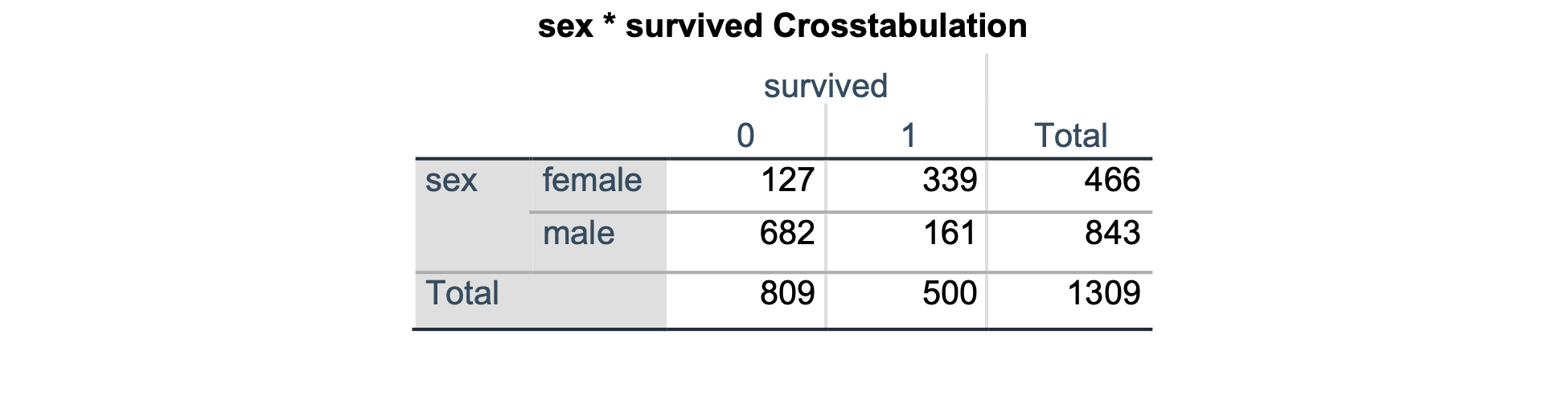
Preživelo je 339 od 466 žensk in 161 od 843 moških. Opazimo, da je preživelo bistveno več potnic ženskega spola. S hi-kvadrat testom preverimo, če je ta razlika statistično značilna.
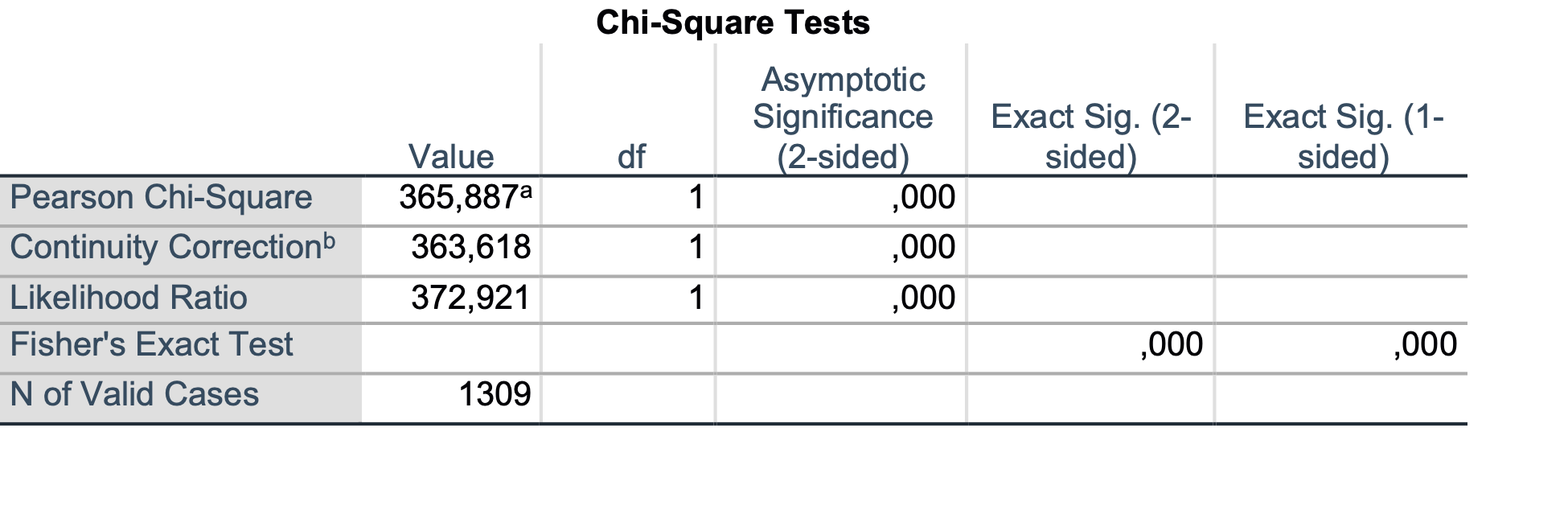
Na podlagi hi-kvadrat testa ugotovimo, da je razlika v deležih preživelih glede na spol statistično značilna (p < 0.001).
Poglejmo še spremenljivko, ki govori o potovalnem razredu.
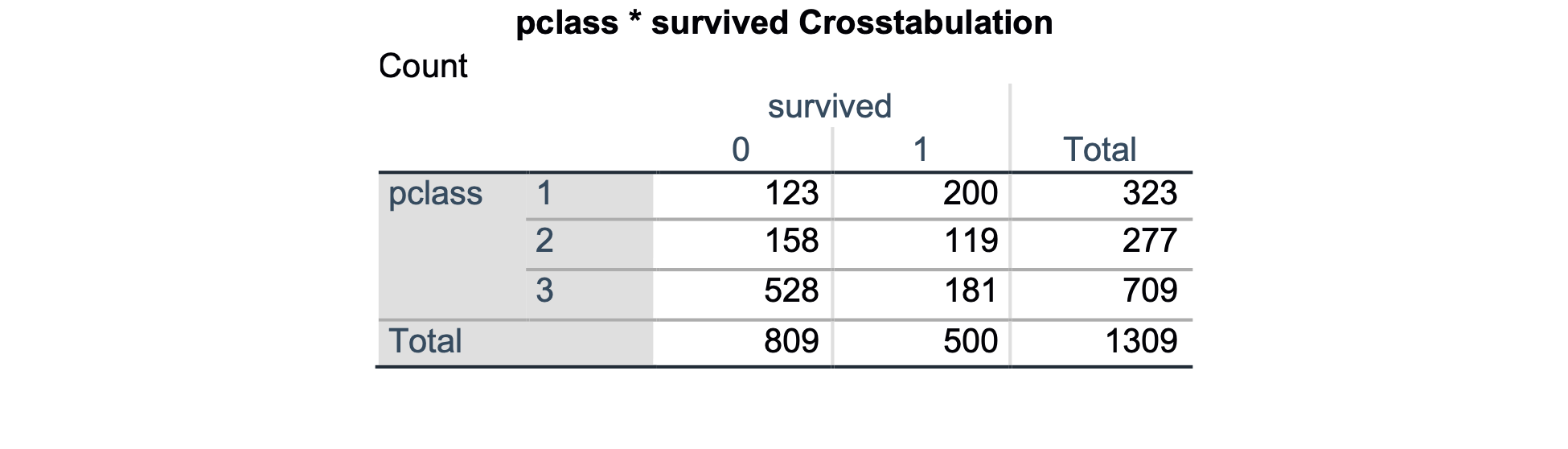
Iz prvega potovalnega razreda je umrlo 123 ljudi od 323, iz drugega potovalnega razreda je umrlo 158 ljudi od 277 in iz tretjega potovalnega razreda je umrlo 528 ljudi od 709. V najnižjem potovalnem razredu jih je umrlo izrazito več kot v najvišjem potovalnem razredu. Preverimo ali je ta razlika statistično značilna s hi-kvadrat testom:
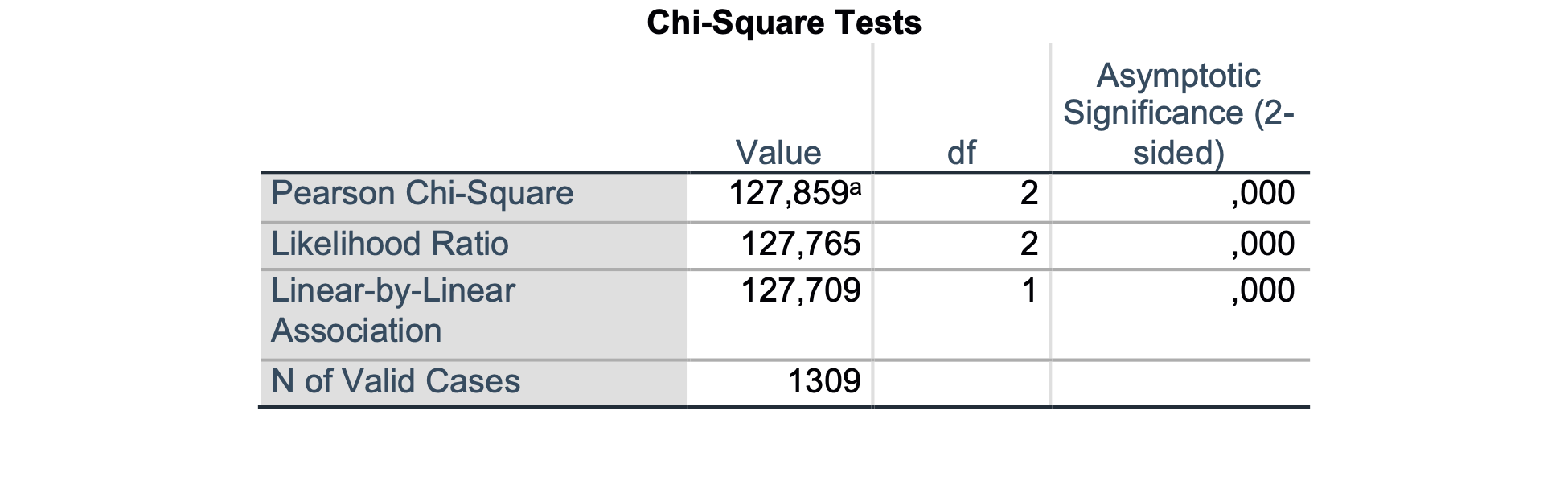
Na podlagi hi-kvadrat testa ugotovimo, da se deleži za preživelost statistično značilno razlikujejo glede na potovalne razrede (p < 0.001).
Pri spremenljivki starost nas zanima, ali je razlika v povprečni starosti umrlih in preživelih. To testiramo s t-testom za neodvisne spremenljivke. Analyze -> Compare means -> Independent T-test. Testna spremenljivka je age, katero razdelimo glede na kategorijsko spremenljivko survived in z ukazom Define Groups … definiramo skupini 0 in 1:
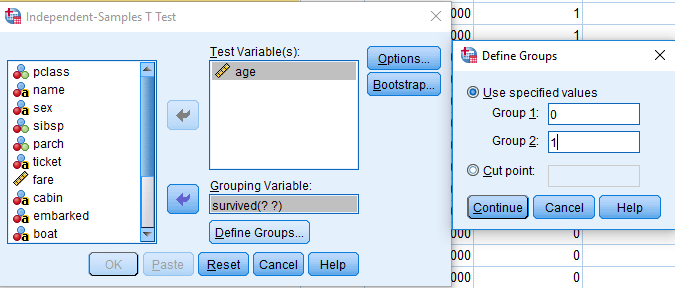
V izvedbenem oknu SPSS se nam izpišejo naslednji rezultati:


Povprečna starost tistih, ki so umrli je 30.5 let, tistih, ki pa so preživeli pa 28.9 let. Na prvi pogled opazimo, da bistvene razlike v povprečni starosti med skupinama ni, kar potrdi tudi vrednost t-statistike. Ker nam test enakosti varianc pove, da sta varianci enaki, gledamo zgornjo p-vrednost v tabeli t-statistike, ki je enaka 0.073. Tako lahko ugotovimo, da ni statistično značilnih razlik v starosti med preživelimi in umrlimi potniki.
Če želimo ugotoviti ali obstaja statistično značilna razlika med potniki, ki so potovali sami in med potniki, ki niso potovali sami, moramo v SPSS programu določiti, katere kategorije spremenljivk sibsp in parch naj program upošteva kot potnike, ki so potovali sami in potnike, ki niso potovali sami.
To naredimo tako, da definiramo novo spremenljivko s Transform -> Compute Variable in jo poimenujemo notalone. Definiramo jo na naslednji način:
(sibsp > 0) | (parch > 0)
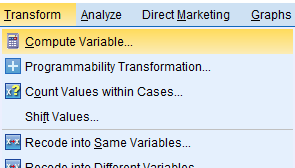
V Data View dobimo nov stolpec s spremenljivko notalone, ki je enaka 1 v primeru, če nisi potoval sam in 0, če si potoval sam.
Nato izrišemo kontingenčno tabelo in izvedemo hi-kvadrat test. Analyze -> Descriptive Statistics -> Crosstabs.
Okno Crosstabs izpolnimo na naslednji način:
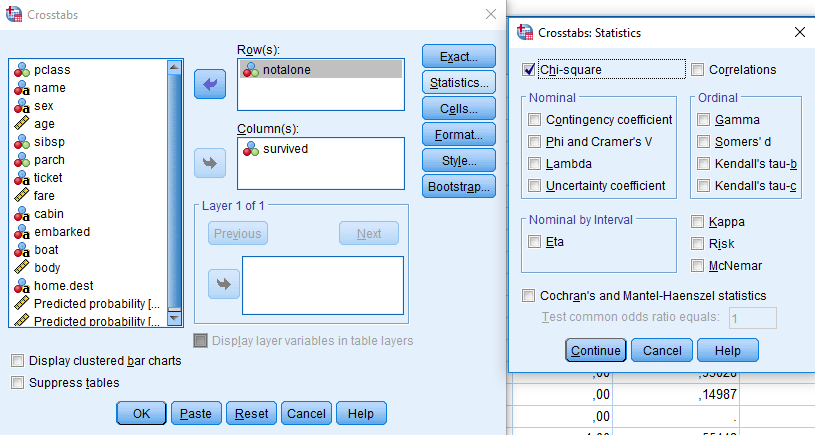
Za spremenljivko v vrsticah kontingenčne tabele izberemo notalone, v stolpcih pa spremenljivko survived. V zavihku Statistics… izberemo test hi-kvadrat. V izvedbenem oknu se nam izrišejo kontingenčne tabele in tabele hi-kvadrat testa.
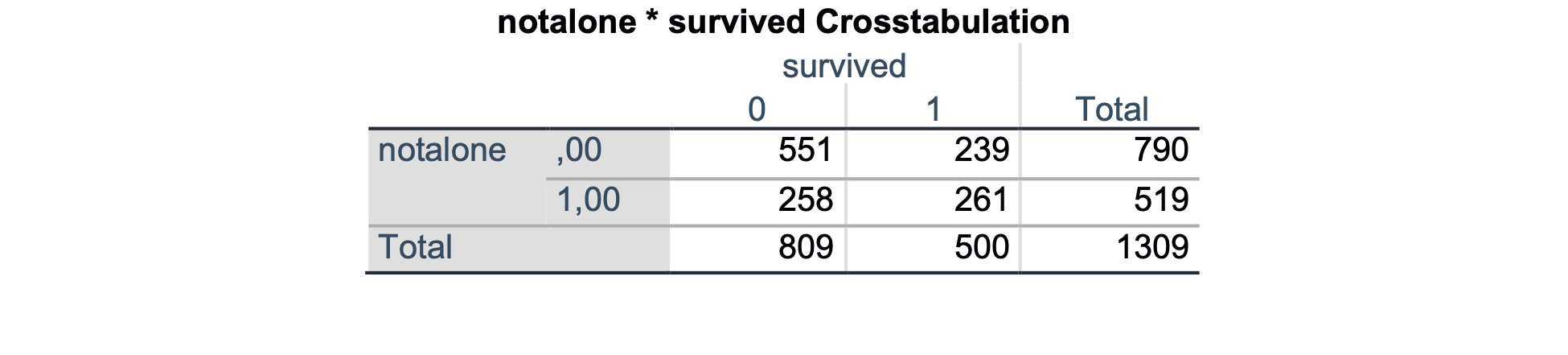
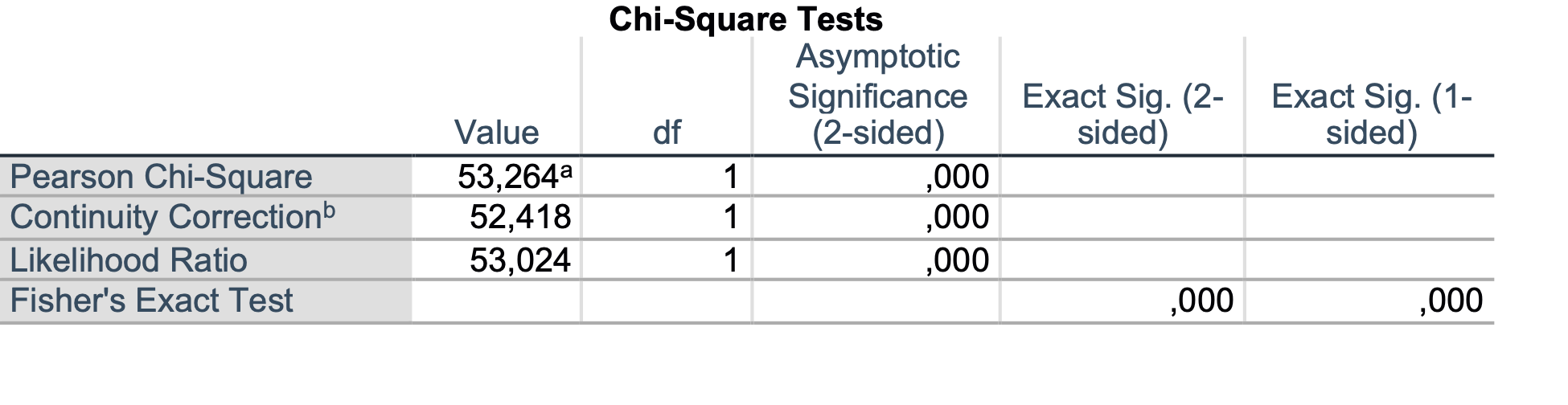
Na podlagi rezultatov tudi tu ugotovimo, da obstajajo statistično značilne razlike med preživelimi in umrlimi glede na to ali so potovali sami ali ne (p < 0.001).
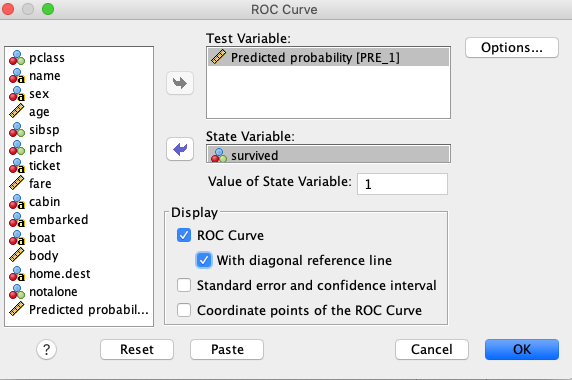
Izvedimo model multiple logistične regresije, kjer bomo modelirali razmerje obetov za preživetje posameznika glede na njegovo starost, spol, razred potovanja in ali je potoval sam ali ne. To izvedemo z ukazom Analyze -> Regression -> Binary Logistic …
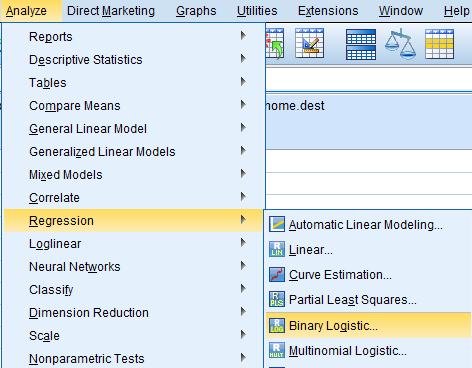
Kot odzivno spremenljivko izberemo survived, kot opisne spremenljivke pa izberemo pclass, sex, age, notalone. Z gumbom Categorical … označimo katere so kategorijske spremenljivke. Zraven imena spremenljivke se pripiše (Cat). Metoda je Enter.
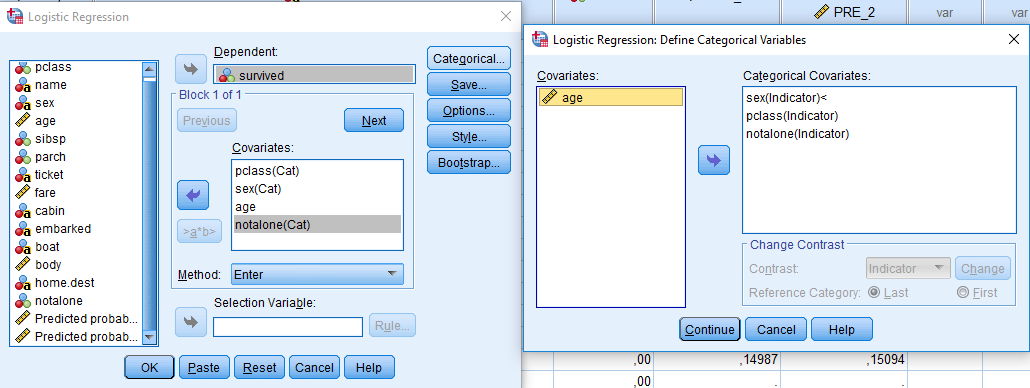
Pri kategorijskih spremenljivkah se računa razmerje obetov glede na referenčno kategorijo. Ob določitvi kategorijskih spremenljivk tudi določimo, da bo referenčna kategorija zadnja.
Za izračun verjetnosti preživetja po modelu logistične regresije moramo še to izbrati s klikom možnost Save … in označimo Probabilities:
Pod možnostmi Options … označimo še CI for exp(B): 95% za izpis intervalov zaupanja v ocene regresijskih parametrov in potrdimo.
V izvedbenem oknu SPSS dobimo naslednje rezultate:
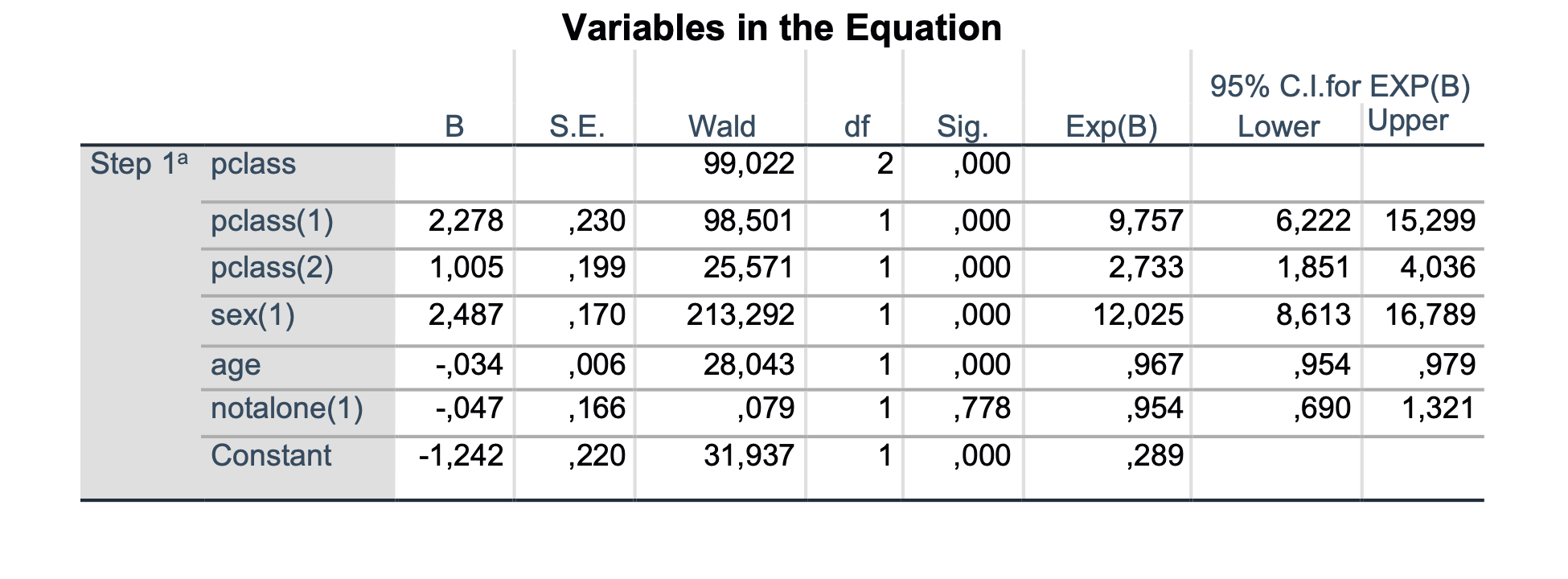
Zanimajo nas predznak regresijskih koeficientov (B), statistična značilnost in Exp(B). Če je vrednost regresijskih koeficientov pozitivna pomeni, da se razmerje obetov za preživetje povečuje, če pa je negativna pa se razmerje obetov preživetja zmanjšuje. Statistična značilnost nam pove ali je regresijski koeficient od nič statistično značilno različen. Ugotovimo, da so statistično ustrezni parametri pclass, sex in age, parameter notalone pa ni statistično značilno od nič različen (p = 0.778), kar pomeni, da to, ali je nekdo potoval sam ali ne, ni statistično pomemben dejavnik za preživetje. Vrednosti Exp(B) predstavljajo razmerja obetov za preživetje za posamezne regresijske spremenljivke. Na podlagi vrednosti v tabeli ugotovimo naslednje:
Potniki prvega razreda so imeli 9.757-krat večjo verjetnost preživetja kot potniki tretjega razreda (Referenčna kategorija je zadnja kategorija, torej potniki tretjega razreda). Potniki drugega razreda so imeli 2.733-krat večjo verjetnost, da so preživeli kot potniki tretjega razreda. Ker noben od intervalov zaupanja ne vsebuje 1.0, sta ta razmerja obetov statistično značilna.
Pri spremenljivki spol, ugotovimo, da so imele ženske 12-krat večjo verjetnost preživetja kot moški (moški so referenčna kategorija).
Pri spremenljivki starost nam vrednost 0.967 pove, da se možnost preživetja zmanjša za 0.967-krat z vsakim letom starosti. Interval ne vsebuje 1.0, kar pomeni, da je to statistično značilno zmanjšanje.
Kakovost logističnega modela predstavljata naslednji tabeli:

Podatki v tabeli govorijo o izračunanem determinacijskem koeficientu, ki po prvem izračunu znaša 0.338, po drugem pa 0.457. Tako lahko zaključimo, da je determinacijski koeficient modela med 0.338 in 0.457, oziroma da z modelom opišemo med 33.8 % in 45.7 % variance preživelih.
Učinkovitost modela za pravilno napovedovanje preživetja na podlagi modeliranih spremenljivk preberemo iz tabele:
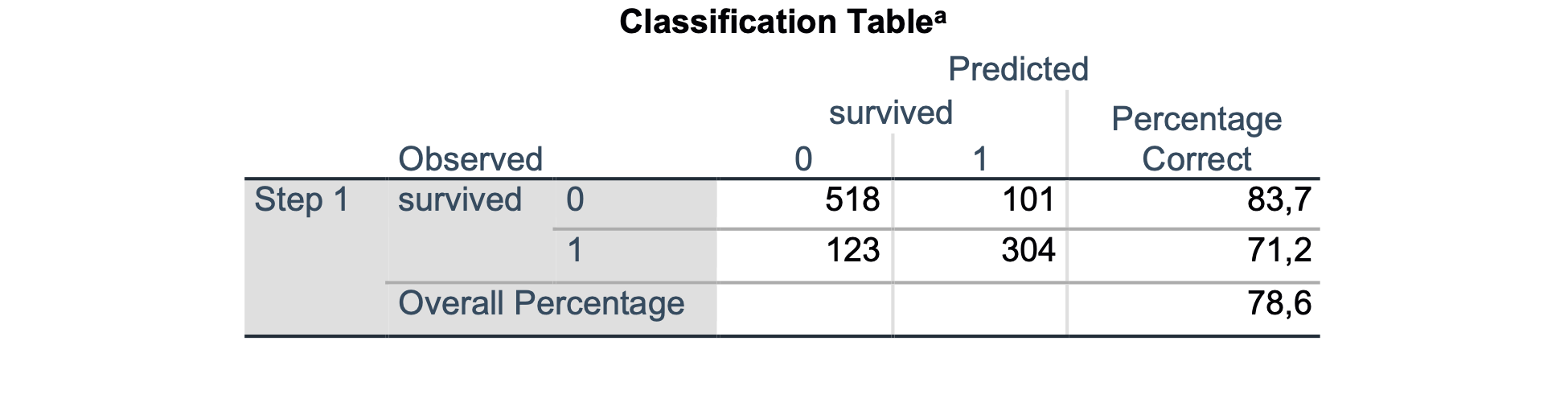
Tabela predstavlja kontingenčno tabelo napovedovanja preživetja, če za mejno vrednost verjetnosti preživetja pri logističnem modelu izberemo verjetnost 0.5. Verjetnost modela nad 0.5 pomeni preživetje, verjetnost pod 0.5 pa ne. V tem primeru pravilno napovemo 518 umrlih in 304 preživele, s skupno točnostjo 78,6 %.
Ustreznost modela za napovedovanje preživelih pa lahko preverimo tudi z ROC analizo. To naredimo z ukazom Analyze -> ROC Curve …, kjer za Test Variable izberemo Predicted probability (to je verjetnost modela, da je posameznik preživel) za State variable pa spremenljivko survived:
V tem primeru se nam izriše ROC krivulja in izračuna AUC:
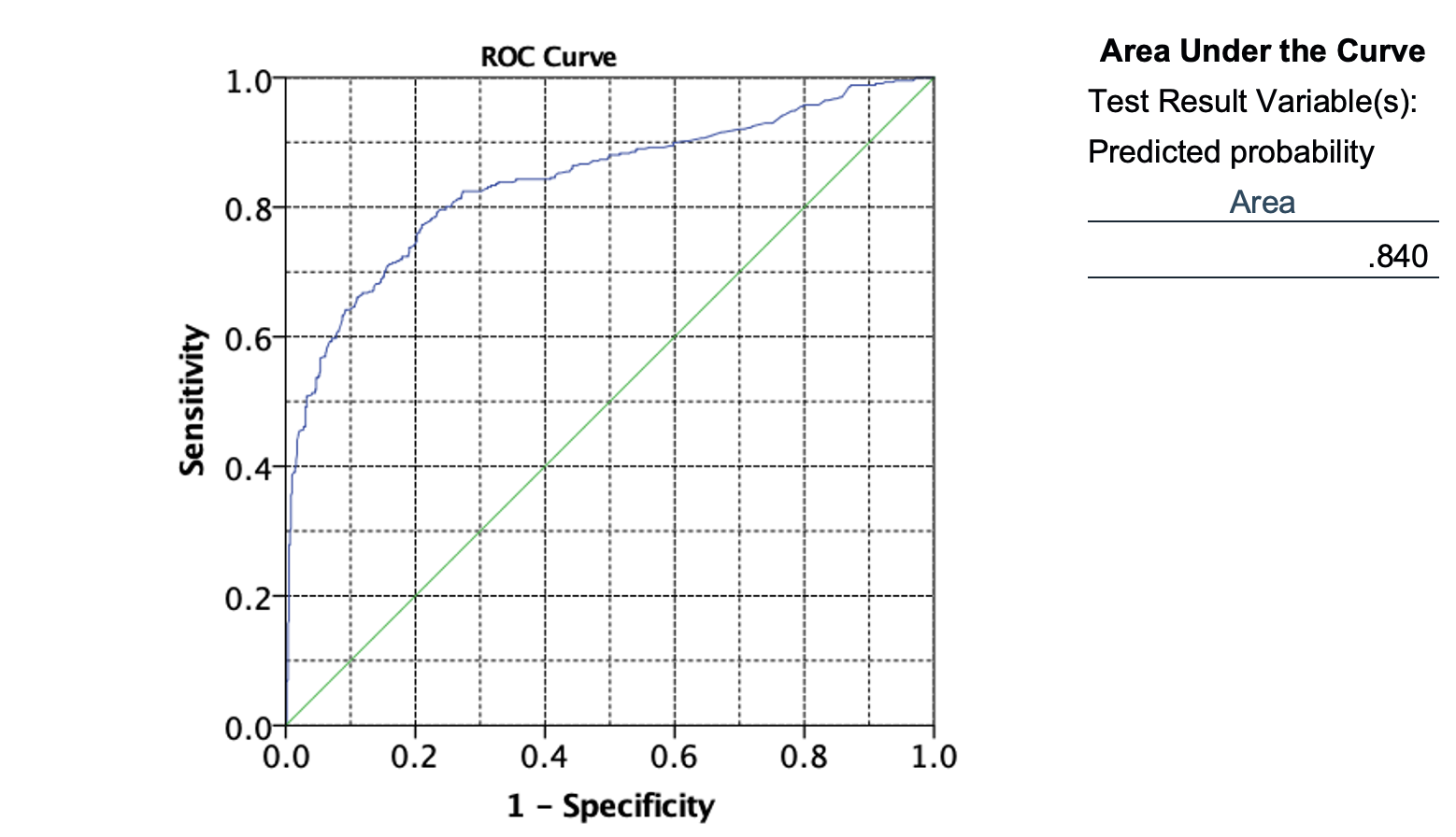
Lahko ugotovimo, da je AUC za napovedovanje preživelih z modelom logistične regresije iz spremenljivk starosti, spola, potovalnega razreda enaka 0.840, kar je dobro.