1 Osnovni pojmi statistične analize
1.1 Vnos podatkov v SPSS in osnovna opisna statistika
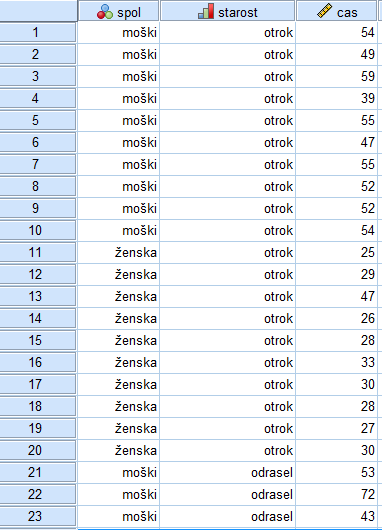
Iz podane tabele ugotovimo, da imamo 3 spremenljivke: spol, starostna skupina in čas. Spol in starostna skupina sta kategorijski spremenljivki, saj imamo pri spolu dve kategoriji: moški, ženska, pri starostni skupini pa tri: otroci, odrasli, starejši. Čas je skalarna spremenljivka.
Odpremo prazen dokument v SPSS programu in v Variable View definiramo spremenljivke tako, kot prikazuje naslednja slika.

Pri Values smo določili vrednosti spremenljivke. Pri spolu pomeni 0-moški spol in 1-ženski spol, pri starostni skupini pomeni 0-otrok, 1-odrasel in 2-starejši. To naredimo tako, da v stolpcu Values kliknemo na vrstico spremenljivke spol in tako kot je prikazano spodaj določimo vrednosti in oznake posameznih skupin. Podobno naredimo tudi pri spremenljivki starost.
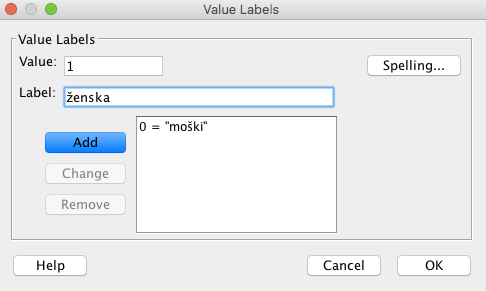
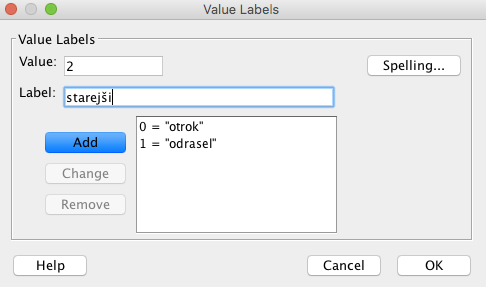
Opozoriti velja, da je spremenljivka spol kategorijska nominalna spremenljivka, saj njene vrednosti ne morejo biti urejene, kategorijska spremenljivka starost pa je ordinalna spremenljivka, saj vrednosti spremenljivke lahko urejamo po velikosti.
Ko smo si pripravili spremenljivke, v Data View vpišemo podatke iz podane tabele. Imamo izmerjene čase pri šestdesetih osebah, zato mora biti izpolnjenih 60 vrstic v Data View. Tabela je organizirana tako, da vsaka vrstica v SPSS programu predstavlja podatke o eni osebi (to je najbolj priporočljiva organiziranost podatkov v tabelah v zdravstvu).
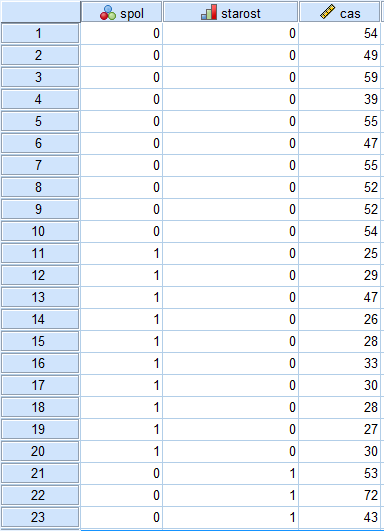
Z ukazom Value labels lahko preklopimo med vrsto zapisa podatkov.
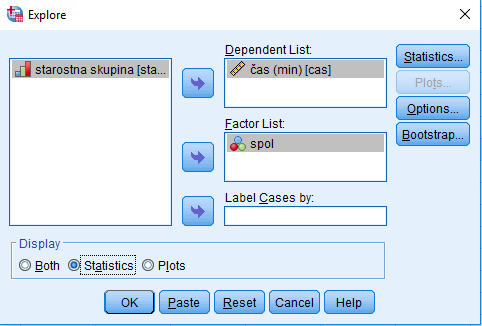
Izvedemo opisno statistiko glede na spol: Analyze -> Descriptive Statistics -> Explore. Zanima nas povprečni čas v minutah, ko se po zaužitju zdravila telesna temperature zniža pod dovoljeno mejo, glede na spol, zato za odvisno spremenljivko izberemo čas, faktorska spremenljivka pa je spol. Za izpis izberemo samo statistiko, zato v oknu Explore pod oznako Display označimo Statistics.
Odpre se nam izvedbeno okno s tabelo, ki prikazuje opisno statistiko. Ker imamo skalarno spremenljivko, nas za primerjavo med skupinami faktorja (spol) zanimata povprečje in standardni odklon. Iz tabele razberemo povprečje in standardni odklon časa v minutah pri moških in ženskah.
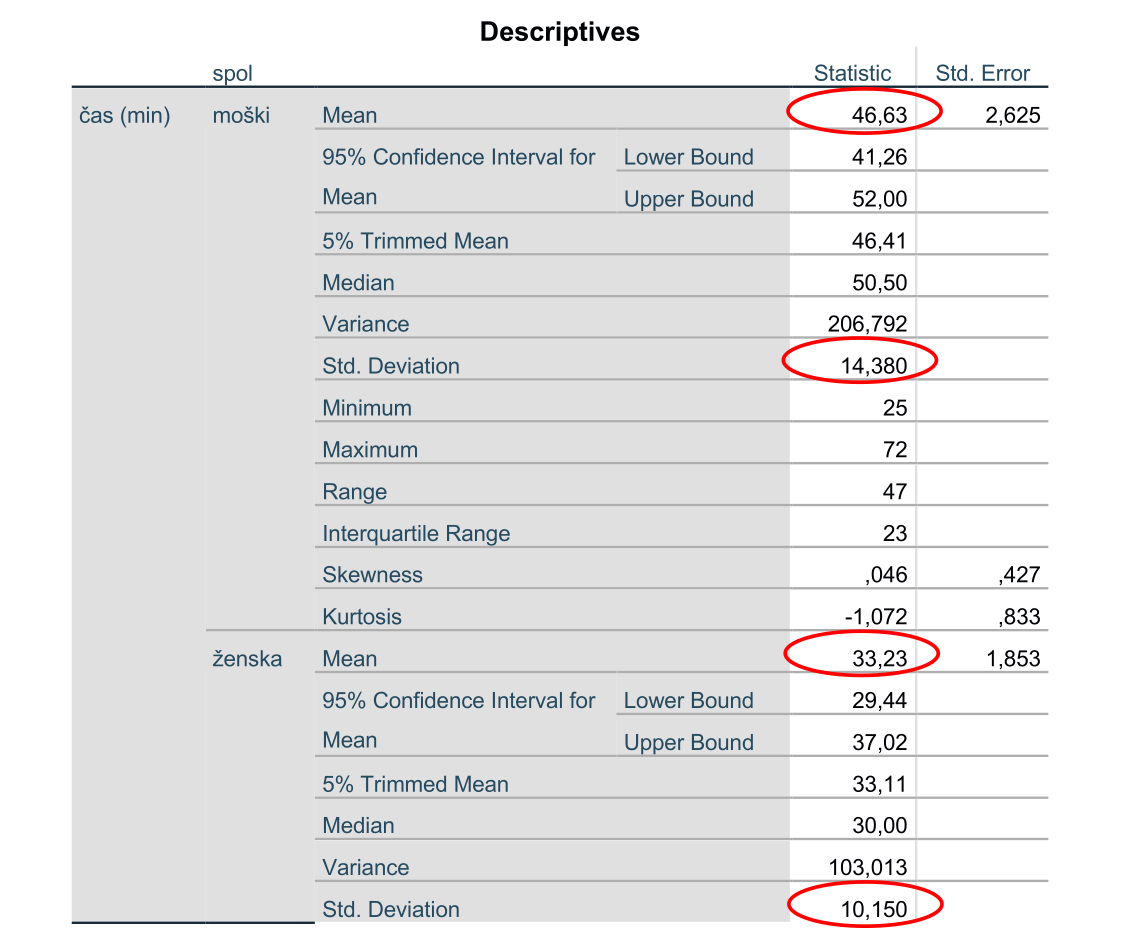
Rezultate lahko predstavimo v naslednji tabeli:
| SPOL | ||
|---|---|---|
| moški | ženski | |
| ČAS [min] | 46.6 ± 14.4 | 33.2 ± 10.2 |
V povprečju se pri moškem spolu po 46.6 ± 14.3 minutah od zaužitja zdravila telesna temperatura zniža pod dovoljeno mejo. Pri ženskem spolu se v povprečju od zaužitja zdravila telesna temperatura zniža pod dovoljeno mejo po 33.2 ± 10.2 minutah. Opazimo, da v povprečju pri moškem spolu zdravilo začne učinkovati po daljšem času kot pri ženskem spolu.
Izvedemo opisno statistiko podatkov glede na starostne skupine: Analyze -> Descriptive Statistics -> Explore. Zanima nas povprečni čas v minutah, ko se po zaužitju zdravila telesna temperatura zniža pod dovoljeno mejo, glede na starostno skupino, zato za odvisno spremenljivko izberemo čas, faktorska spremenljivka je starostna skupina.
Enako kot prej se nam odpre izvedbeno okno. Iz tabele opisne statistike izpišemo povprečje in standardni odklon za vsako starostno skupino posebej. Rezultati so predstavljeni v naslednji tabeli:
| STAROSTNA SKUPINA | |||
|---|---|---|---|
| Otroci | Odrasli | Starejši | |
| ČAS [min] | 41.0 ± 12.4 | 51.4 ± 11.2 | 27.5 ± 5.9 |
Ugotovimo, da v povprečju pri starejših zdravilo učinkuje v najkrajšem času, pri odraslih mora v povprečju miniti največ časa. Standardni odkloni nam pokažejo, da so pri starejši starostni skupini izmerjeni časi bolj homogeni (standardni odklon je manjši), pri drugih skupinah pa izmerjeni časi od zaužitja zdravila do učinkovanja bolj variirajo (standardni odklon je večji).
Zanima nas čas od zaužitja zdravila do učinkovanja zdravila glede na oba faktorja skupaj (spol in starostne skupine). Najprej pripravimo podatke tako, da jih bomo posebej obravnavali glede na starostno skupino. To naredimo tako, da izvedemo ukaz: Data -> Split file -> Compare groups by: starostna skupina.
Zdaj bomo izvedli opisno statistiko glede na spol in glede na starostne skupine hkrati. Program ve, da mora posebej obravnavati podatke glede na starostno skupino, zato moramo izbrati še ukaz za izvedbo opisne statistike glede na spol: Analyze -> Descriptive Statistics -> Explore. Odvisna spremenljivka je čas v minutah, faktor pa spol.
V izvedbenem oknu se nam odpre tabela, ki pokaže opisno statistiko glede na spol in starostne skupine hkrati. Izsek izpisa je predstavljen spodaj:
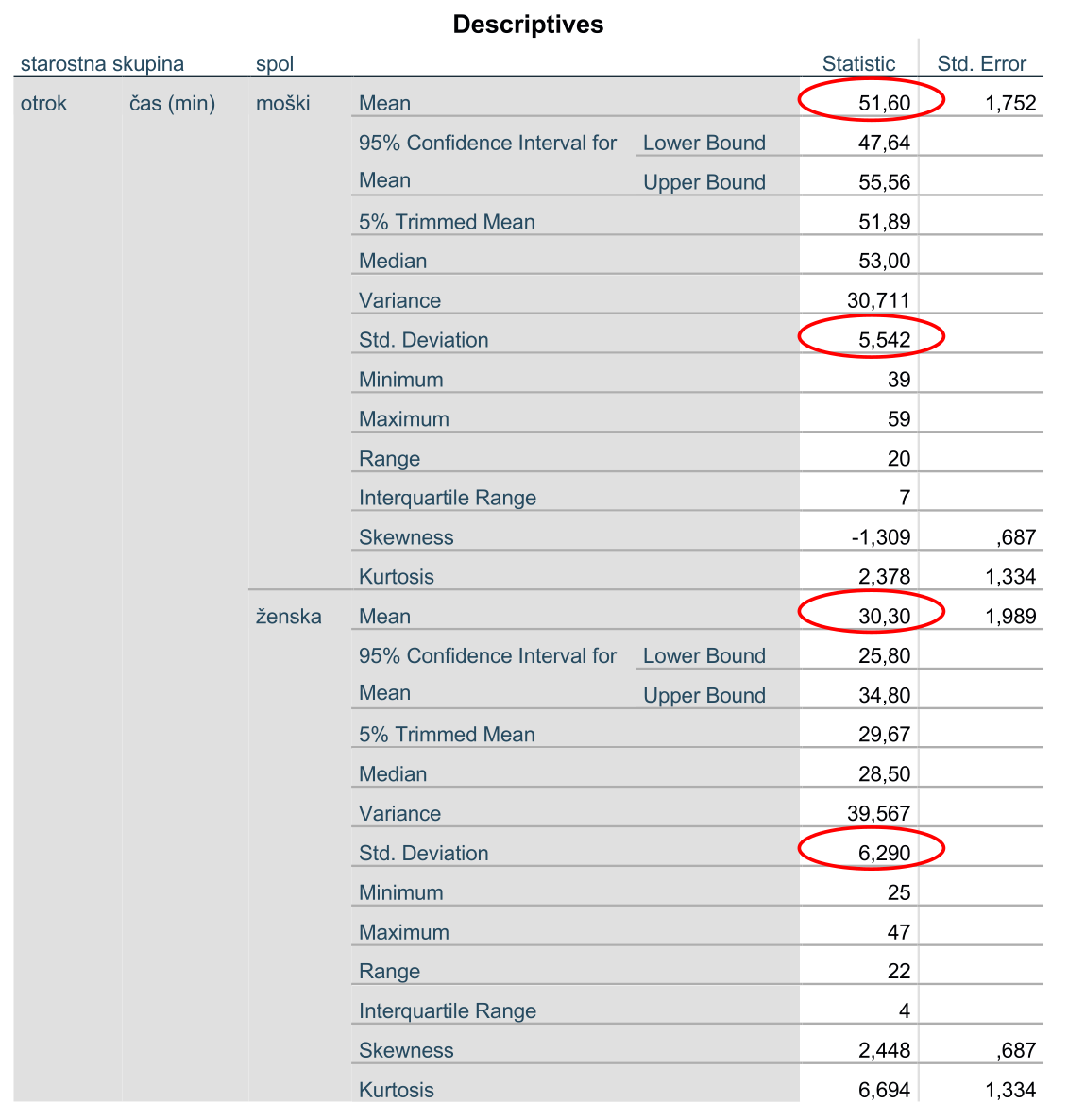
Enako kot prej izpišemo povprečne vrednosti in standardne odklone. Rezultati so predstavljeni v naslednji tabeli:
| STAROSTNA | SKUPINA | |||||
|---|---|---|---|---|---|---|
| Otroci | Odrasli | Starejši | ||||
| SPOL | M | Ž | M | Ž | M | Ž |
| ČAS [min] | 51.6 ± 5.5 | 30.3 ± 6.3 | 58.7 ± 10.7 | 44 ± 5.6 | 29.6 ± 3.1 | 25.4 ± 7.4 |
Primerjamo povprečne čase po spolih pri posameznih starostnih skupinah. Ugotovimo, da obstajajo razlike v povprečnih časih pri otrocih in odraslih med moškimi in ženskami. Povprečni čas učinkovanja zdravila med spoloma pri starejših pa se ne razlikuje toliko kot v ostalih skupinah.
1.2 Grafi pri statistični analizi
Definirajmo osnovna raziskovalna vprašanja, ki jih lahko preverimo:
Ali obstaja statistično značilna razlika v času, ko se po zaužitju zdravila telesna temperatura zniža pod dovoljeno mejo glede na spol?
Ali obstaja statistično značilna razlika v času, ko se po zaužitju zdravila telesna temperatura zniža pod dovoljeno mejo glede na starostno skupino?
Ali obstaja statistično značilna razlika v času, ko se po zaužitju zdravila telesna temperatura zniža pod dovoljeno mejo glede na spol in starostno skupino?
Podatke moramo grafično prikazati tako, da bomo na podlagi grafov lahko preverjali hipoteze izpeljane iz zastavljenih raziskovalnih vprašanj.
Preverimo prvo raziskovalno vprašanje: Ali obstaja statistično značilna razlika v času, ko se po zaužitju zdravila telesna temperatura zniža pod dovoljeno mejo glede na spol?
To bomo preverili z grafom okvir z ročaji (ang. boxplot). Graf prikazuje porazdelitev skalarnih spremenljivk.
Narišimo boxplot z ukazom Graphs -> Chart Builder…
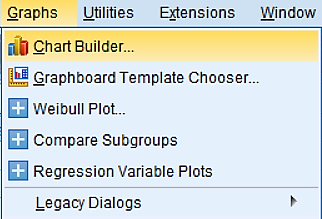
Primerjali bomo spremenljivko cas glede na spremenljivko spol. Uporabili bomo graf boxplot, zato ga poiščemo v spodnjem levem okvirčku v zavihku Gallery. Opazimo, da imamo na izbiro tri vrste boxplotov. V tem primeru izberemo prvo vrsto boxplota, ki ga povlečemo v polje. Spremenljivko spol prenesemo na x-os, spremenljivko cas pa na y-os, kot prikazuje slika.
V izvedbenem oknu SPSS se izrišeta grafa okvir z ročajem, ki sta prikazana spodaj.
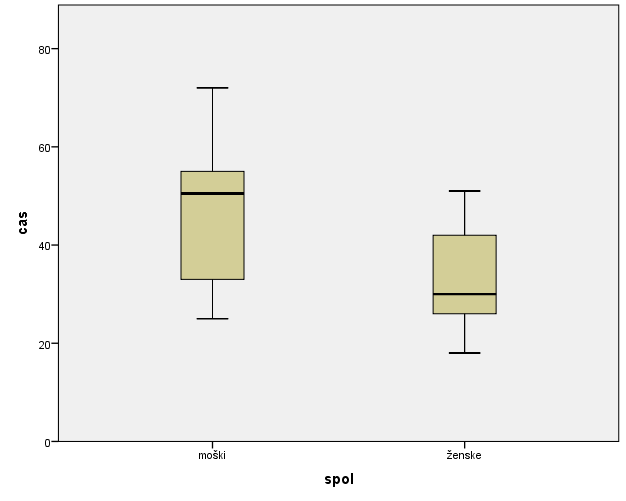
Grafa okvirja z ročajem prikazujeta porazdelitev meritev časa padca telesne temperature ločeno po spolu. Okvir grafa predstavlja meritve med 1. in 3. kvartilom, črta znotraj okvirja grafa predstavlja mediano meritev, ročaji grafa pa so dolgi 1.5 medkvartilne razdalje navzdol oziroma navzgor od mediane. Iz dobljenih grafov lahko ugotovimo, da grafa nista simetrična glede na neenako razdaljo med mediano ter 1. kvartilom in mediano ter 3. kvartilom, zato na podlagi tega lahko sklepamo, da verjetno meritve časa niso normalno porazdeljene. Mediana enega grafa leži zunaj intervala med 1. in 3. kvartilom drugega grafa, zato lahko potrdimo, da obstaja statistično značilna razlika v času med spoloma.
Preverimo drugo raziskovalno vprašanje: Ali obstaja statistično značilna razlika v času, ko se po zaužitju zdravila telesna temperatura zniža pod dovoljeno mejo glede na starostno skupino?
Narišimo graf okvir z ročaji oziroma boxplot z ukazom Graphs -> Chart Builder…
Primerjali bomo spremenljivko cas glede na spremenljivko starost. Spremenljivko starost prenesemo na x-os, spremenljivko cas pa na y-os, kot prikazuje slika.
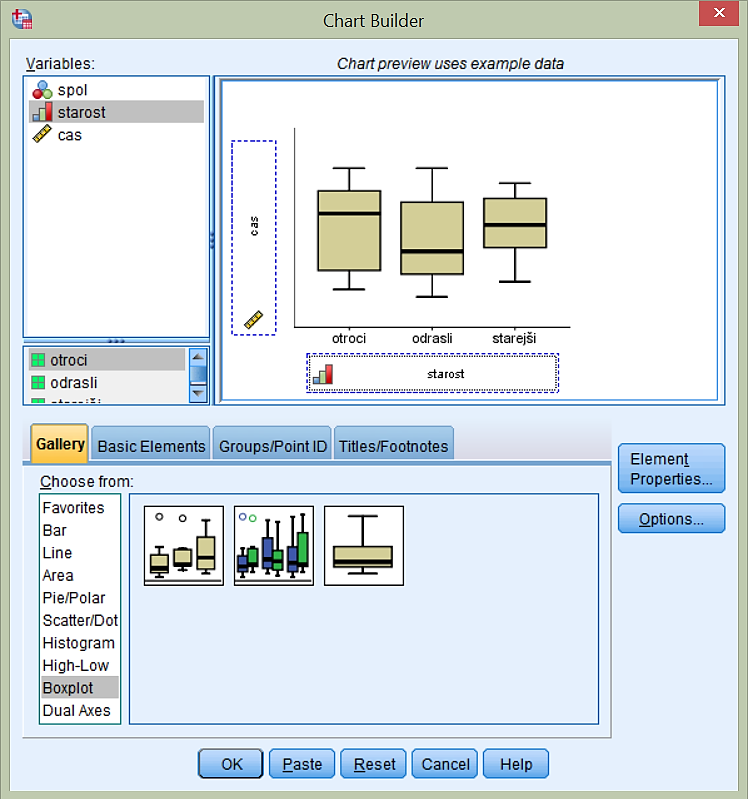
SPSS izriše naslednji graf:
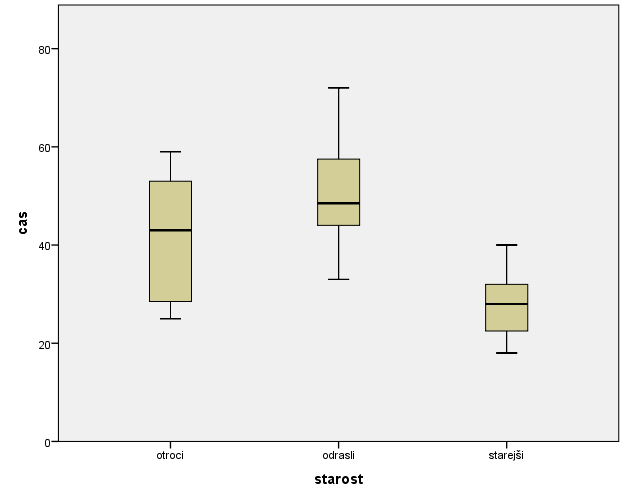
Ugotovimo, da skupina starejših izrazito odstopa od skupine odraslih in skupine otrok, saj mediana grafa skupine starejših ne seka območja znotraj 1. in 3. kvartila grafov skupine odraslih in skupine otrok. Skupina starejših je zato statistično značilno različna od skupine odraslih in od skupine otrok. Med skupino odraslih in skupino otrok pa ne moremo na podlagi grafa okvir z ročaji z gotovostjo trditi, da gre za statistično značilne razlike med njimi.
Preverimo tretje raziskovalno vprašanje: Ali obstaja statistično značilna razlika v času, ko se po zaužitju zdravila telesna temperatura zniža pod dovoljeno mejo glede na spol in starostno skupino?
Ponovno izrišemo graf okvir z ročaji, vendar pa izberemo druge vrste izris, saj imamo zdaj dva faktorja – starostno skupino in spol, zato izberemo graf boxplot različnih barv.
Spremenljivko starost prenesemo na x-os, spremenljivko cas pa na y-os. Spol prenesemo v okvirček Cluster on X. Spol (moški, ženske) bo prikazan v dveh različnih barvah.
SPSS izriše naslednji graf.
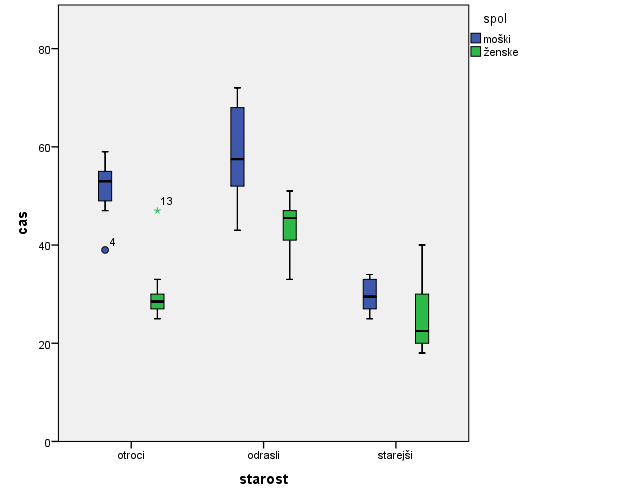
Ugotovimo, da se moški in ženske v starostni skupini otrok med seboj izrazito statistično značilno razlikujejo. Tudi v starostni skupini odraslih se moški in ženske razlikujejo, vendar nekoliko manj kot pri otrocih, še manj pa se razlikujejo moški in ženske glede na čas v starostni skupini starejših.
Pri primerjavi moških skupine otrok s skupino odraslih ugotovimo, da ni statistično značilnih razlik, medtem ko med moškimi skupine otrok in starejših ter odraslih in starejših statistično značilne razlike so.
Pri primerjavi žensk vseh treh starostnih skupin ugotovimo, da med skupino otrok in starejših ne obstajajo statistično značilne razlike, med skupino odraslih in starejših pa obstajajo statistično značilne razlike, prav tako pa tudi med skupino otrok in odraslih.
V skupini otrok vidimo še dve odstopajoči meritvi (osamelec), in sicer 4. in 13. meritev po vrsti v naših podatkih.
Da lahko grafično ocenimo, ali so porazdelitve podatkov po posameznih skupinah normalno porazdeljene, bomo narisali graf kvartil-kvartil ali QQplot: Analyze -> Descriptive Statistics -> Explore… Z gumbom Plots… označimo Normality Plots with tests.
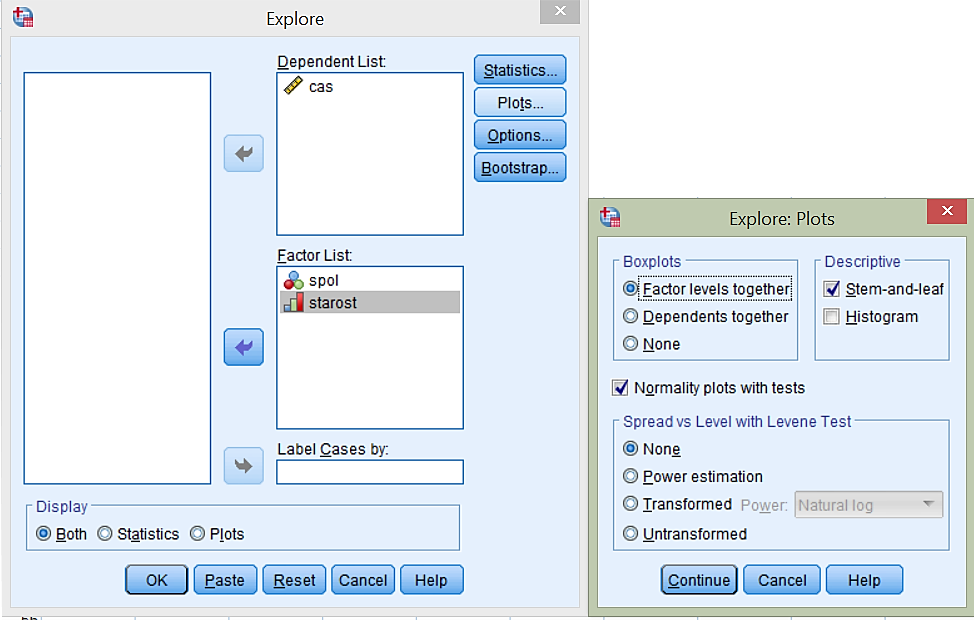
V izvedbenem oknu se nam izrišejo kvartil-kvartil grafi, ki so prikazani spodaj.
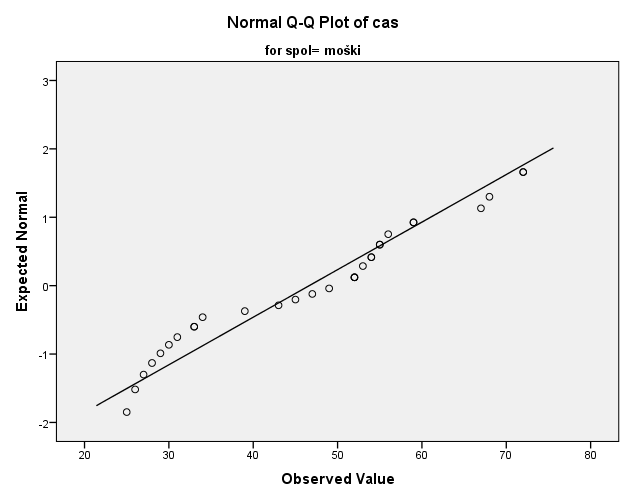
Subjektivno ocenimo, da podatki skupine moški niso normalno porazdeljeni, saj se podatki ne prilegajo premici kvartil-kvartil grafa, ampak od nje odstopajo z značilnim vzorcem v obliki črke S. Bolj kot podatki odstopajo od premice kvartil-kvartil, z večjo verjetnostjo lahko trdimo, da podatki niso normalno porazdeljeni.
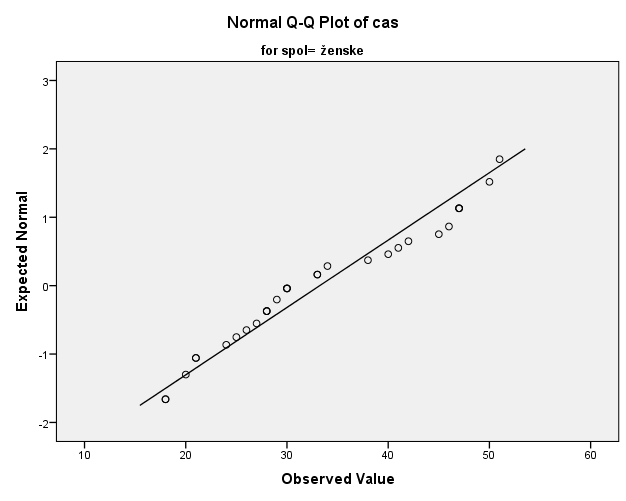
Tudi pri skupini žensk po subjektivnem mnenju ugotovimo, da podatki niso normalno porazdeljeni. Vendar je odstopanje manjše kot v primeru moških. Zato lahko zaključimo, da je večja verjetnost, da so meritve časa v ženski skupini normalno porazdeljene kot pri moških.
Poglejmo še kvartil-kvartil grafe glede na starostne skupine.
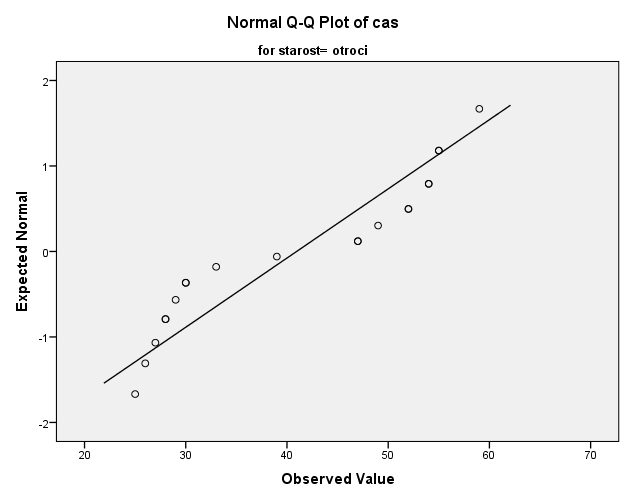
Tukaj lahko z gotovostjo trdimo, da podatki starostne skupine otrok niso normalno porazdeljeni, saj vidimo velika odstopanja od premice kvartil-kvartil grafa in značilni vzorec v obliki črke S.
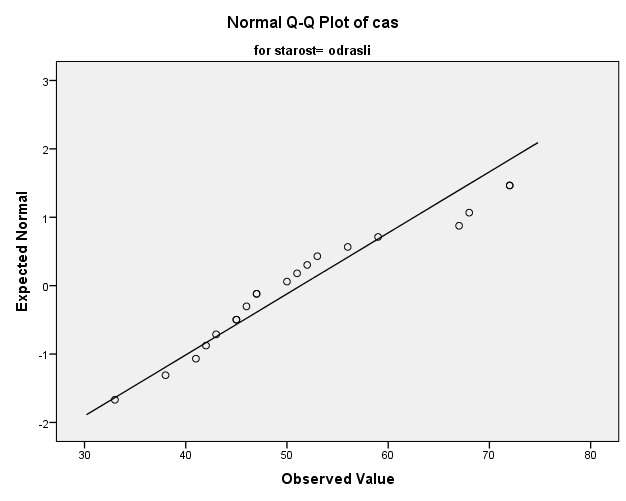
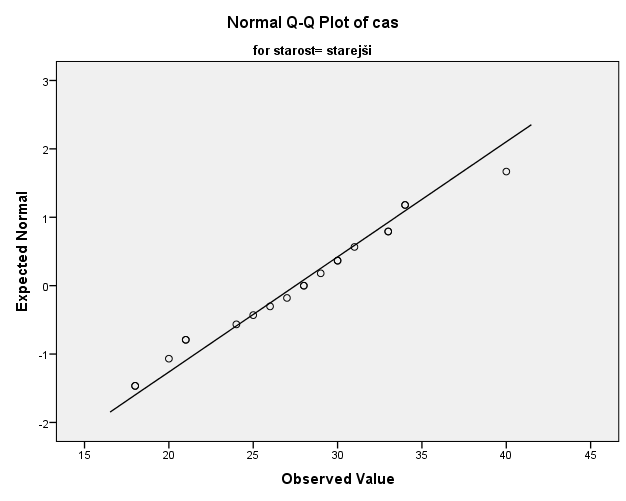
Podobno lahko ugotovimo tudi pri meritvah časa pri starostni skupini odraslih, medtem ko so odstopanja pri skupini starejših manjša, kar pomeni večjo verjetnost, da so te meritve normalno porazdeljene.
Glede na vse tri kvartil-kvartil grafe ločene po starostni skupini lahko trdimo, da je večja verjetnost, da so meritve časa starostne skupine starejših normalno porazdeljene, medtem ko je verjetnost, da so meritve starostne skupine otroci in odrasli normalno porazdeljene, manjša.
1.3 Statistike za ugotavljanje oblike porazdelitve podatkov
Uvozimo podatke iz Excel datoteke v SPSS z ukazom File -> Import data -> Excel… in izberemo datoteko kreatinin_akin_pacienti.xlsx.
V zavihku Variable View preverimo in po potrebi popravimo lastnosti spremenljivk (Measure, Decimals, Width, …).

V teh podatkih nas zanimajo samo podatki o starosti, zato bomo v nadaljevanju delali s podatki spremenljivke starost.
Če hočemo podati frekvenčno analizo meritev starosti, bomo spremenljivko starost razdelili na starostne intervale po 10 let. To bomo naredili tako, da bomo uvedli novo spremenljivko starostne skupine, kjer bodo kategorije predstavljale starostne skupine po 10 let (od 21 do 30 let, od 31 do 40 let, od 41 do 50 let, ipd.). To naredimo z ukazom: Transform -> Visual Binning in za spremenljivko izberemo Variables to Bin = starost:
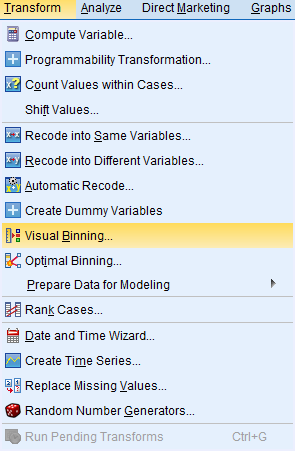
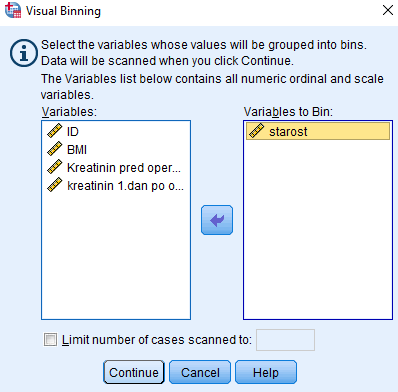
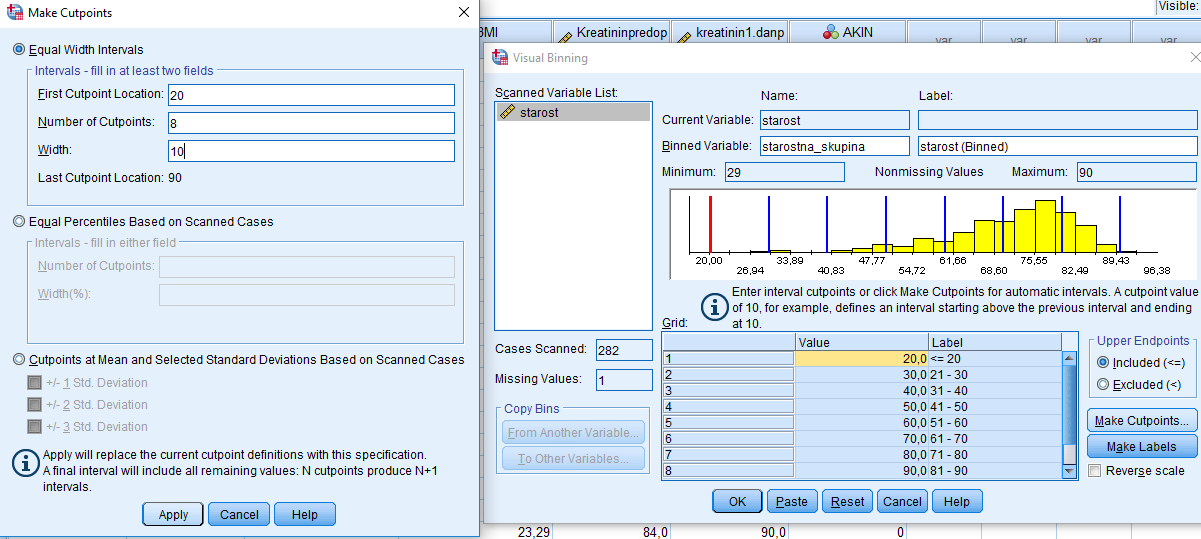
Odpre se nam novo okno, ki ga izpolnimo po naslednjem postopku: Binned Variable: starostna_skupina, pod gumbom Make Cutpoints določimo First Cutpoint Location = 20, Width = 10, Number of Cutpoints = 8 in potrdimo z Apply, nato označimo možnost Make Labels in pritisnemo OK.
Novo spremenljivko uporabimo za frekvenčno analizo pacientov po starosti. Analyze -> Descriptive Statistics -> Frequencies, kjer izberemo novo spremenljivko starostna_skupina. V izvedbenem oknu dobimo naslednjo tabelo:
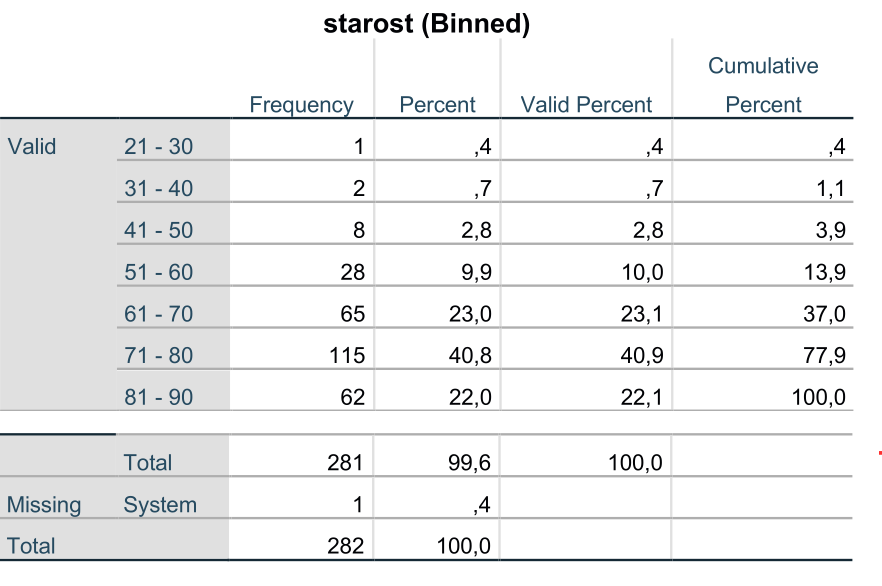
Iz frekvenčne tabele lahko razberemo, koliko ljudi spada v določen starostni razred. Ugotovimo, da je največ pacientov starih med 71 in 80 let, kar pomeni, da se bo med tema vrednostima najverjetneje nahajalo povprečje.
Izračunajmo povprečje, mediano in najpogostejšo meritev spremenljivke starost: Analyze
-> Descriptive Statistics -> Frequencies, kjer izberemo spremenljivko starost, potem pa z gumbom Statistics… označimo Mode, Median, Mean.
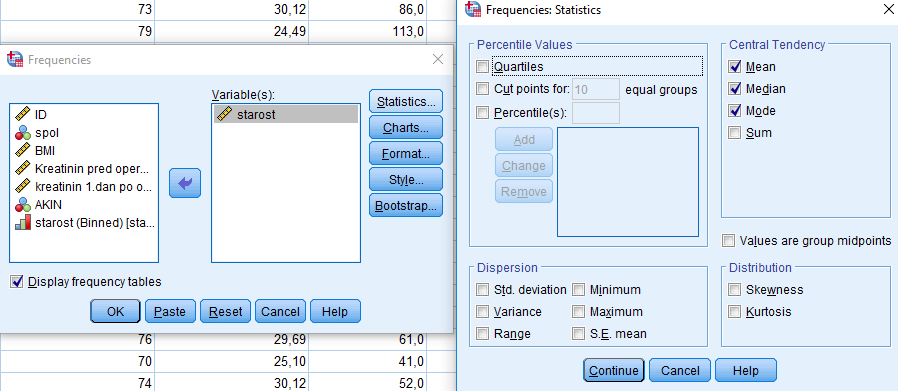
Iz rezultatov v spodnji tabeli razberemo, da je povprečje enako 71.6 let, mediana 74 let in najpogostejša meritev 77 let. Opazimo, da so te vrednosti različne med seboj, kar pomeni, da porazdelitev meritev ni simetrična, torej podatki niso normalno porazdeljeni. V primeru simetričnih porazdelitev so te vrednosti enake.
Percentile izračunamo z ukazom: Analyze -> Descriptive Statistics -> Frequencies…, kjer izberemo spremenljivko starost, potem pa z gumbom Statistics… določimo katere percentile hočemo, kot je prikazano spodaj:
V izvedbenem oknu dobimo naslednje statistike:
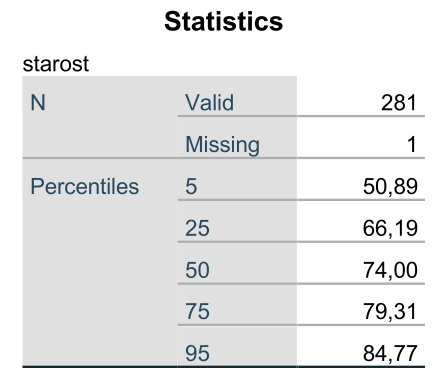
Glede na razlike med vrednostmi posameznih percentilov lahko ugotovimo, da je porazdelitev nesimetrična. Je raztegnjena v levo in strmo padajoča v desno.
1.4 Delo s porazdelitvami – normalna porazdelitev
V SPSS-u ustvarimo nekaj novih spremenljivk, katerih vrednosti bodo rezultati oziroma odgovori na vprašanja naloge.
V zavihku Variable View pripravimo 10 skalarnih spremenljivk, ki jih poimenujemo s p1 do p10, kot je prikazano spodaj:
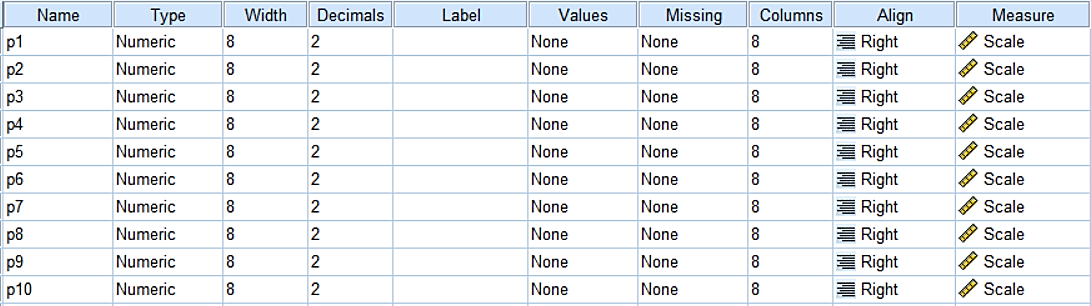
V zavihku Data View moramo sedaj rezervirati mesta za vpis, sicer nam SPSS kasneje ne bo izpisoval izračunanih vrednosti. Vstavimo na primer vrednost 0 za spremenljivko p1. Tako SPSS-u nakažemo, da bomo napolnili eno vrstico.

V zavihku Data View se nam bodo izpisovale izračunane vrednosti spremenljivk.
Izvedemo ukaz Transform -> Compute Variable…
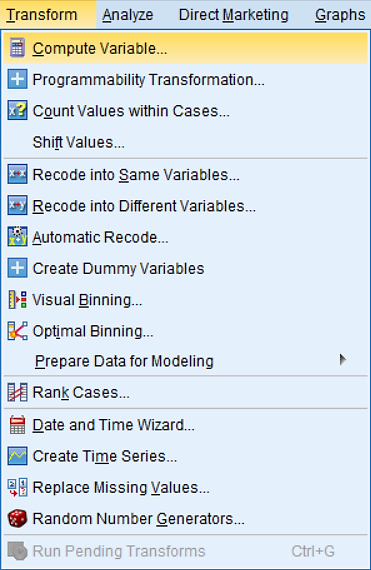
Kakšna je verjetnost, da bo doza na pacienta večja od 9 enot?
Za izračun vrednosti prve spremenljivke bomo uporabili CDF funkcijo. V oknu Target Variable levo zgoraj izpišemo vrednost katere spremenljivke nas zanima (p1 v tem primeru). V oknu Function group izberemo vrsto porazdelitve CDF & Noncentral CDF in pod Functions and Special Variables Cdf.Normal, saj gre v našem primeru za normalno porazdelitev podatkov.
Ker iščemo verjetnost, da bo doza na pacienta večja od 9 enot, je potrebno izračunati verjetnost s funkcijo CDF na naslednji način: 1-CDF(9).

V SPSS: 1-CDF.NORMAL (9, 7, 1.5).
Rešitev: p1 = 0.09 se nam izpiše v zavihku Data View.
Verjetnost, da bo doza na pacienta večja od 9 enot je 0.09 oziroma 9 %.
Tak postopek ponovimo za vsako spremenljivko posebej, kjer glede na vrednost, ki jo želimo izračunati izberemo ustrezno funkcijo.
Kakšna je verjetnost, da bo doza med 6 in 8 enotami?
Ker iščemo verjetnost, da bo doza na pacienta med 6 in 8 enotami, je potrebno izračunati verjetnost s CDF na naslednji način: CDF(8)-CDF(6).
V SPSS: p2 = CDF.NORMAL(8,7,1.5)−CDF.NORMAL(6,7,1.5)
Rešitev: p2 = 0.5
Verjetnost, da bo doza med 6 in 8 je 0.5 oziroma 50 %.
Kakšna je doza, ki je presežena v 90 % meritev?
IDF funkcija je inverzna funkcija CDF. IDF je mejna vrednost meritve x, pri kateri je CDF(x) = p.
Zanima nas, pri kateri vrednosti je CDF enak 0.1. Torej katera je tista vrednost doze (M), ki jo preseže 90 % pacientov. Poiskati moramo rešitev za M, da bo CDF(M) = 0.1.
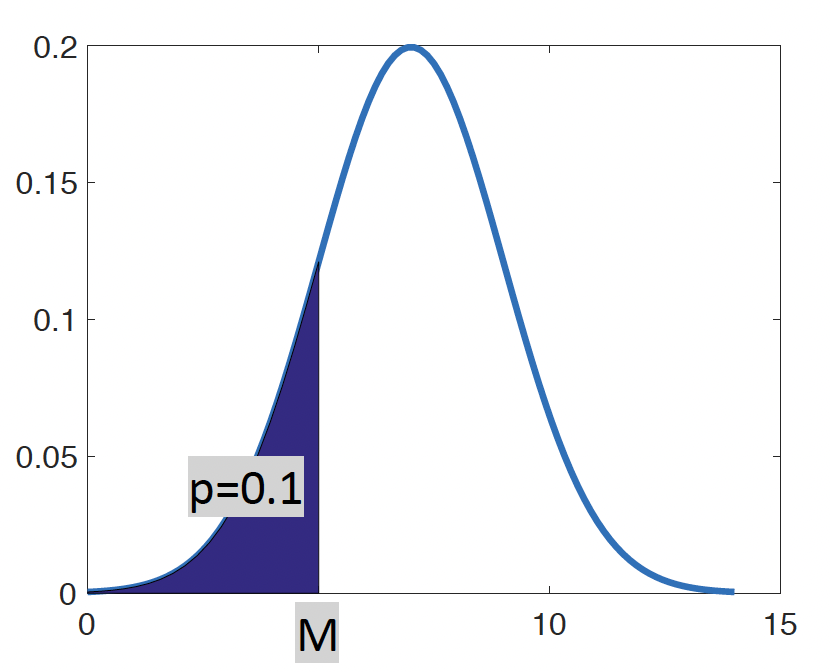
To izvedemo z izračunom v SPSS: IDF.NORMAL(0.1,7,1.5)
Rešitev: p3 = 5,08
Vrednost doze, ki je presežena v 90 % meritev je 5,08 enot.
Kakšna je pričakovana vrednost 1. in 3. kvartila naših meritev in koliko znaša medkvartilna razdalja?
Medkvartilna razdalja je razdalja med 1. in 3. kvartilom. Izračunamo jo tako, da od vrednosti 3. kvartila odštejemo vrednost 1. kvartila.
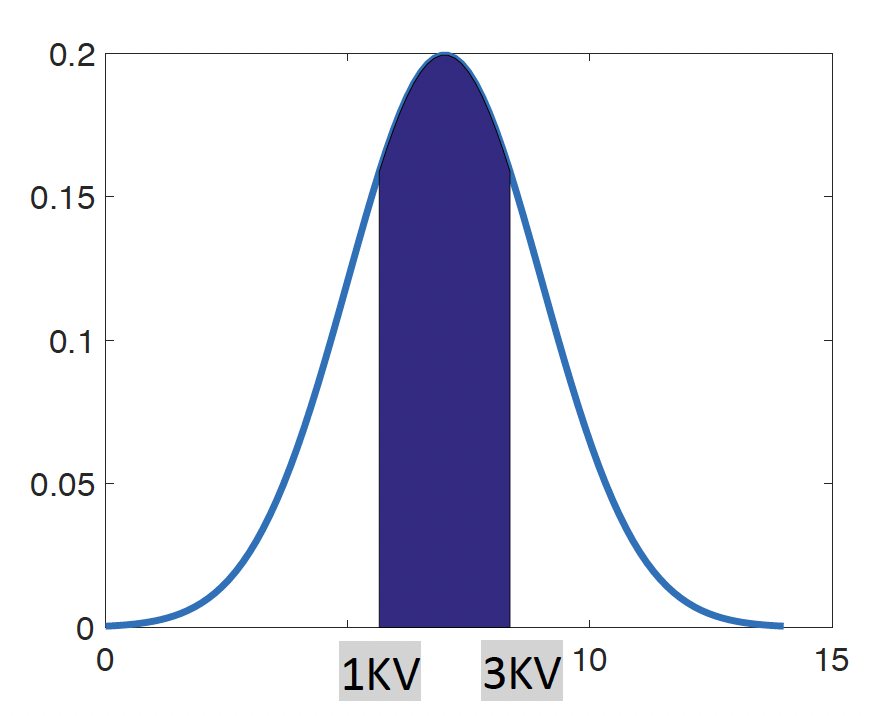
Vrednost 1. kvartila izračunamo z IDF(0.25), vrednost 3. kvartila pa z IDF(0.75). Medkvartilna razdalja je IDF(0.75) - IDF(0.25).
V SPSS:
| 1. kvartil: | IDF.NORMAL(0.25,7,1.5) = 5.99 |
| 3. kvartil: | IDF.NORMAL(0.75,7,1.5) = 8.01 |
| IQR: | IDF.NORMAL(0.75, 7,1.5) - IDF.NORMAL(0.25, 7,1.5) = 2.02 |
Na katerem intervalu se nahaja 95 % vseh meritev?
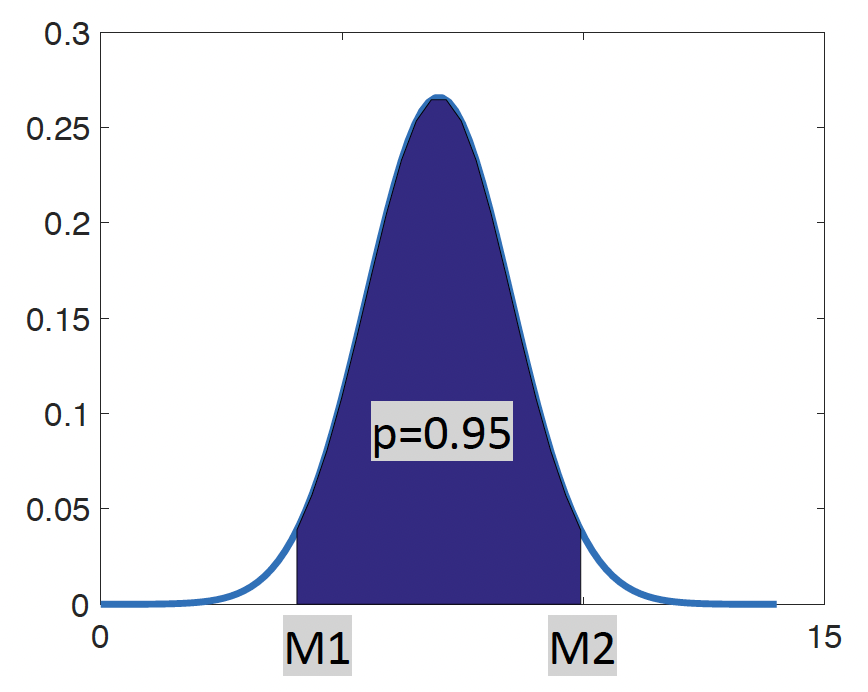
V tem primeru nas zanimata dve vrednosti doz: spodnja vrednost doze (M1) in zgornja vrednost doze (M2), ki oklepata interval 95 % vseh meritev okrog povprečja.
Vrednost M1 izračunamo z IDF(0.025), vrednost M2 pa z IDF(0.975).
V SPSS:
| M1 = IDF.NORMAL(0.025,7,1.5) = 4.06 |
| M2 = IDF.NORMAL(0.975,7,1.5) = 9.94 |
95 % vseh meritev doz se nahaja na intervalu med 4.06 in 9.94.
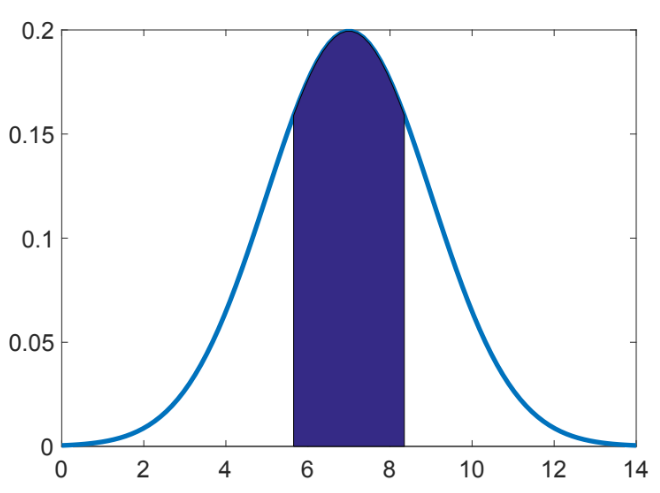
Kakšen bi moral biti standardni odklon, da bi lahko trdili, da bo v 99 % primerov doza manjša od 8 enot?
Spreminjati moramo standardni odklon normalne porazdelitve toliko časa, dokler ne bo CDF(8,7,s) = 0.99. Pri tem se spreminja oblika normalne porazdelitve, kot je prikazano na sliki.
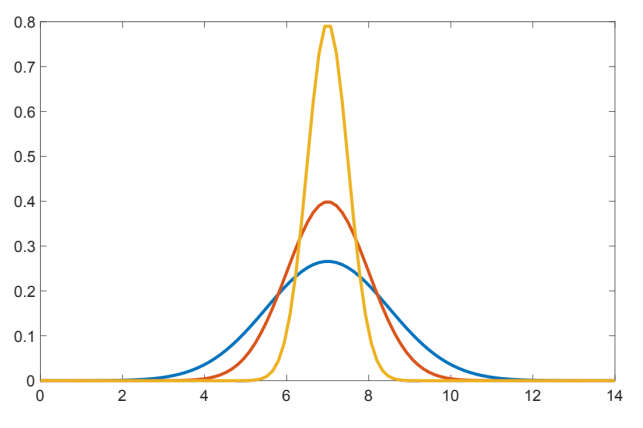
V SPSS v ukaz CDF.NORMAL(8,7,s) tako dolgo vstavljamo poljubne vrednosti standardnega odklona s, dokler ni vrednost CDF = 0.99. To se zgodi pri standardnem odklonu 0.4.
Slika prikazuje, kako se v Data View izpisujejo vrednosti spremenljivk.

1.5 Delo s porazdelitvami – binomska porazdelitev
V tem primeru imamo opravka z binomsko porazdelitvijo. To je porazdelitev verjetnosti, ko nas zanima, kakšna je verjetnost \(x\) izidov (v kakršnem koli vrstnem redu) v \(N\) dogodkih v primeru, ko je verjetnost enega izida \(p\). Porazdelitev računamo po naslednji formuli:
\[PDF(x) = \begin{pmatrix} N \\ x \end{pmatrix}p^{x}{(1 - p)}^{N - x},\]
kjer je \(x\) število izidov v \(N\) dogodkih, \(p\) je verjetnost enega izida, binomski simbol \(\small \begin{pmatrix} N \\ x \end{pmatrix}\) pa predstavlja število vseh kombinacij \(x\) izidov v \(N\) dogodkih. Primer binomske porazdelitve predstavlja met kovanca. Če se sprašujemo, kakšna je verjetnost, da vržemo 3 cifre v 10-ih metih kovanca ob verjetnosti, da vržemo cifro p = 0.5, to izračunamo na naslednji način:
\[PDF(3) = \begin{pmatrix} 10 \\ 3 \end{pmatrix}{0.5}^{3}{(1 - 0.5)}^{7} = 0.1172.\]
Razlaga zgornjega izračuna je naslednja. Število kombinacij, da vržemo 3 cifre v 10-ih metih, izračunamo z \(\small \begin{pmatrix} 10 \\ 3 \end{pmatrix}\), verjetnost, da vržemo 3 cifre je \({0.5}^{3}\), verjetnost, da vržemo preostalih 7 grbov pa \({(1 - 0.5)}^{7}\). Vrednost 0.1172 je verjetnost, da vržemo 3 cifre v 10-ih metih.
Na podoben način lahko obravnavamo verjetnost v našem primeru. Verjetnost, da pacient umre zaradi infarkta je \(p=0.04\), \(N = 10\), \(x\) pa je odvisen od naloge, ki jo rešujemo.
Odpremo prazen dokument v SPSS programu. V Variable View si pripravimo 3 spremenljivke: p1, p2 in p3. Vse tri spremenljivke so skalarji.

Če želimo izračunati točno določen dogodek, v našem primeru točno določeno število pacientov, ki umrejo, uporabimo funkcijo PDF. Imamo binomsko porazdelitev podatkov, saj imamo dva možna izida (pacient umre, pacient ne umre). Transform -> Compute Variable -> PDF & Noncentral PDF -> PDF.Binom. Vrednosti, ki jih vpišemo v oklepaj pri funkciji so najprej število pacientov, ki bodo umrli, nato število vseh pacientov in kot tretje navedemo verjetnost, da pacient umre pri infarktu.
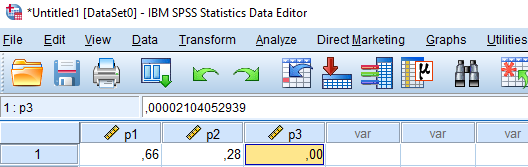
Za izračun spremenljivke p1 – verjetnosti, da noben od pacientov ne umre, izberemo tarčno spremenljivko (p1) in naslednji ukaz: PDF.BINOM (0,10,0.04).
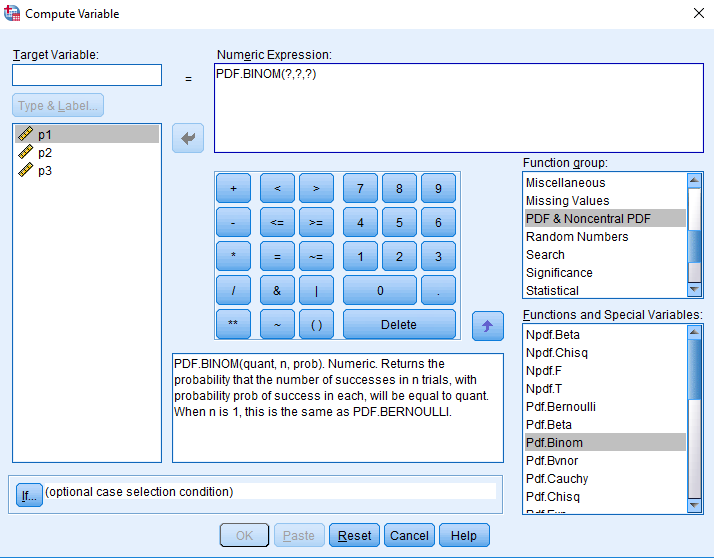
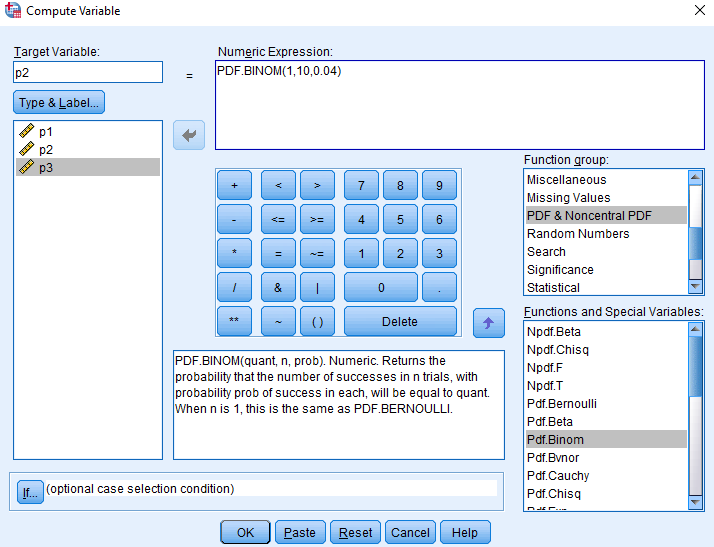
Po enakem postopku izračunamo verjetnost, da bo 1 pacient umrl. Za tarčno spremenljivko izberemo p2, vrednosti funkcije PDF.BINOM(1,10,0.04).
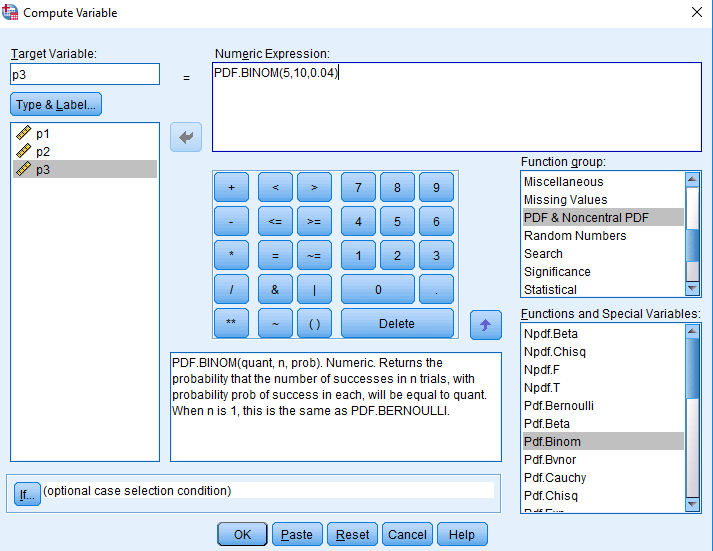
Zanima nas, kakšna je verjetnost, da umre pet od desetih pacientov. Uporabimo enak postopek kot prej, izberemo tarčno spremenljivko p3 in vrednosti funkcije PDF.BINOM(5,10,0.04).
V Data View se nam izpišejo rezultati, ki nam povejo:
Obstaja 66 % verjetnost, da noben od pacientov ne bo umrl (p1 = 0.66).
Obstaja 28 % verjetnost, da bo umrl en pacient (p2 = 0.28).
Obstaja zelo majhna verjetnost (0.002 %), da bo polovica pacientov umrla (p3 = 0.00002).