3 Osnovne statistike v diagnostiki
3.1 Senzitivnost, specifičnost, točnost
Uvozimo podatke iz Excel datoteke v SPSS z ukazom File -> Open -> Data… in v oknu Open data določimo File Type: Excel.
Prebrani podatki so shranjeni v treh spremenljivkah diagsistem1, diagsistem2 in dejanskadiagnoza.
Spremenljivka diagsistem1 predstavlja testno diagnozo prvega diagnostičnega sistema, diagsistem2 predstavlja testno diagnozo drugega diagnostičnega sistema, dejanskadiagnoza pa dejansko referenčno diagnozo, s katero bomo primerjali oba testna diagnostična sistema. Število primerjav je 51.
Za izračun senzitivnosti in specifičnosti, izvedemo statistično analizo z izvedbo ukaza
Analyze -> Descriptive Statistics -> Crosstabs…
Pri izračunu senzitivnosti in specifičnosti diagnostičnega sistema 1 z gumbom Cells… določimo, katere odstotke bomo izpisali v kontingenčni tabeli. Izberemo odstotke po stolpcih, kot je prikazano spodaj:
Enako ponovimo še za diagnostični sistem 2:
V izvedbenem oknu SPSS se izpiše kontingenčna tabela za diagnostični sistem 1 skupaj z želenimi odstotki:
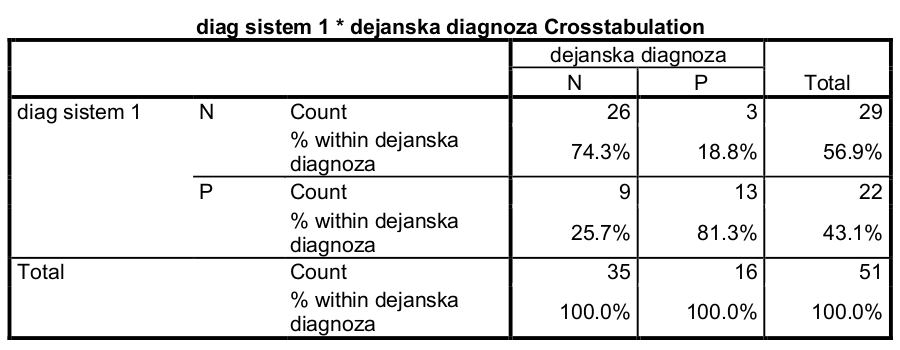
Senzitivnost lahko preberemo iz odstotka celice s pozitivno dejansko diagnozo in pozitivno diagnozo prvega diagnostičnega sistema, torej senzitivnost = 81.3 %. Senzitivnost predstavlja delež, kako dobro testni diagnostični sistem napove pozitivno diagnozo (bolezen) glede na referenčno diagnozo.
Specifičnost lahko preberemo iz odstotka celice z negativno dejansko in negativno testno diagnozo, kar v našem primeru znaša specifičnost = 74.3 %. Specifičnost predstavlja delež pravilno diagnosticiranih negativnih diagnoz (zdravih) v primerjavi z referenčno diagnozo.
V primeru diagnostičnega sistema 2, pa dobimo naslednjo kontingenčno tabelo:
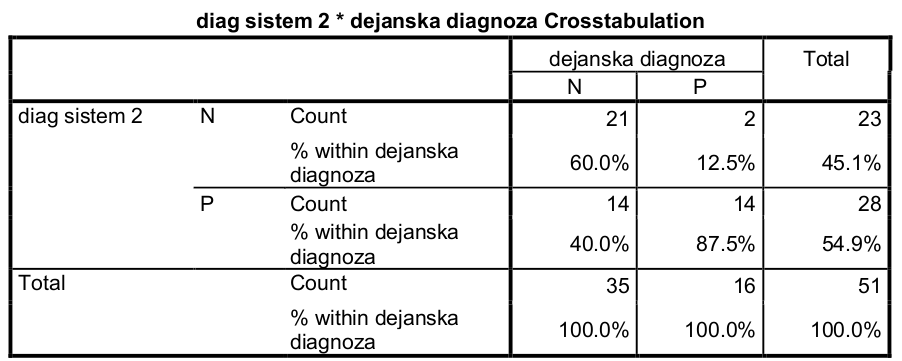
Podobno kot prej iz ustreznih celic preberemo senzitivnost = 87.5 % in specifičnost = 60.0 %.
Točnost obeh diagnostičnih sistemov lahko izračunamo iz kontingenčnih tabel po obrazcu točnost = (TP + TN) / N. V primeru prvega diagnostičnega sistema znaša točnost = (26 + 13) / 51 = 76.5 %, v drugem primeru pa točnost = (21 + 14) / 51 = 68.6 %.
3.2 Krivulja ROC
Z SPSS preberemo podatke iz naloge za statistično analizo. To naredimo tako, da izberemo datoteko z ukazom File -> Open -> Data…
To so dejanski podatki o pacientih po operaciji na srcu, kjer smo jim merili različne parametre, med drugim tudi kreatinin pred operacijo in kreatinin en dan po operaciji. Del podatkov je prikazan v nadaljevanju:

V našem primeru nas zanimajo spremenljivke KRE_pre_OP, kjer imamo meritve kreatinina pred operacijo, spremenljivka KRE_1dan_PO, kjer imamo meritve kreatinina pri pacientih en dan po operaciji in spremenljivka nonAKIN_AKIN, kjer imamo dejanske diagnoze okvare delovanja ledvic, pri čemer vrednost 1 pomeni okvaro delovanja ledvic, 0 pa ne. Skupaj imamo 263 pacientov.
V tem primeru predstavlja dejansko diagnozo spremenljivka nonAKIN_AKIN, testni diagnozi pa spremenljivki KRE_pre_OP in KRE_1dan_PO, ki sta skalarja. V takšnem primeru testiramo uspešnost napovedovanja dejanske diagnoze z binomsko odločitvijo (odločitvijo, kjer sta možna le dva izida: P ali N, 0 ali 1 ipd.) z uporabo krivulje ROC. To izvedemo z ukazom Analyze -> ROC Curve …
Enako ponovimo še za kreatinin en dan po operaciji:
Pri tem še označimo možnost Coordinate points of the ROC Curve, ki nam bo v pomoč pri ocenjevanju optimalne mejne vrednosti kreatinina.
V izvedbenem oknu SPSS se izrišejo ROC krivulje skupaj z ocenjenimi vrednostmi ploščine pod krivuljo AUC.
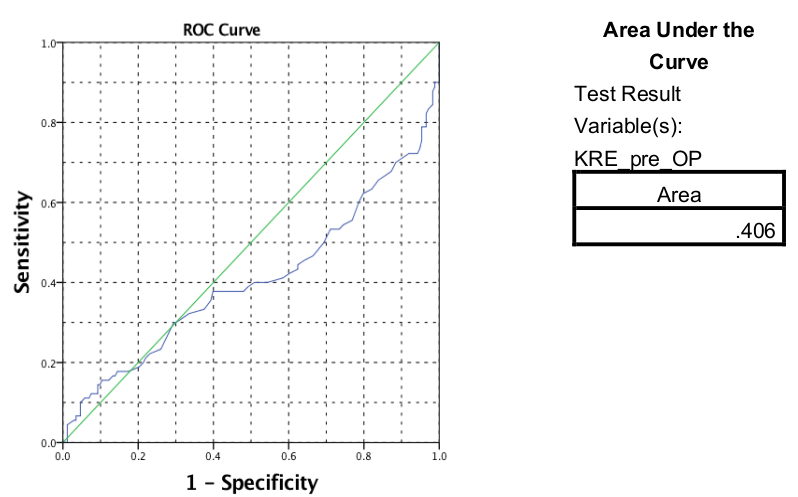
V primeru kreatinina pred operacijo dobimo spodnji graf ROC krivulje z AUC:
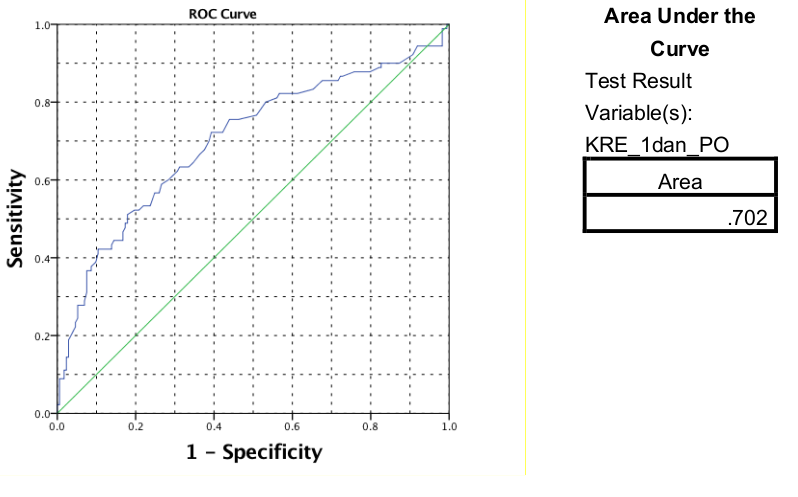
V primeru kreatinina 1 dan po operaciji dobimo spodnji graf ROC krivulje z AUC.
Poleg tega dobimo še tabelo mejnih vrednosti kreatinina spremenljivke KRE_1dan_PO in ustrezne senzitivnosti in specifičnosti:
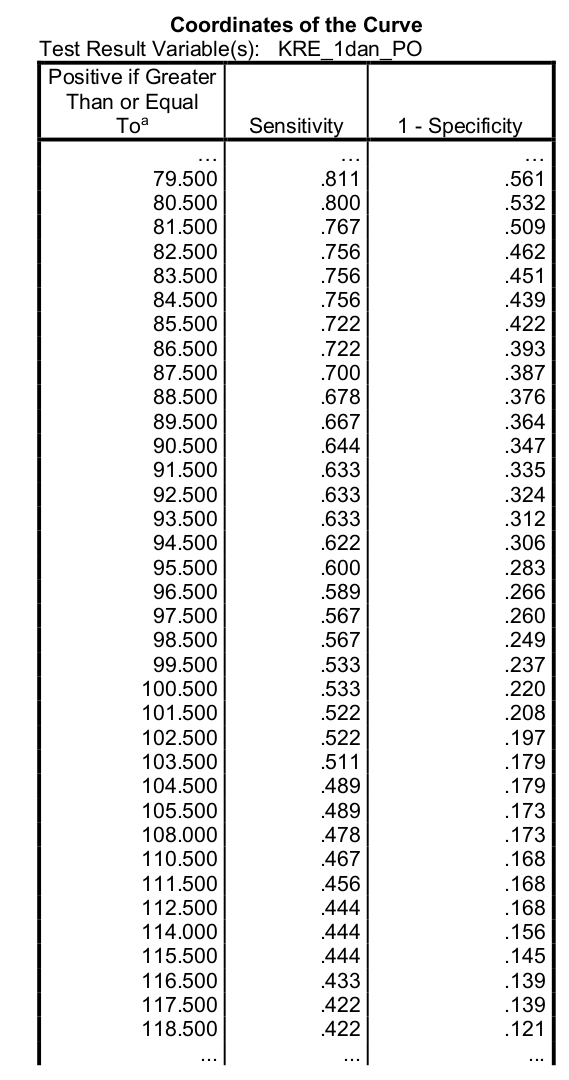
Na podlagi te tabele lahko v primeru spremenljivke KRE_1dan_PO ugotovimo, pri kateri mejni vrednosti dobimo najbolj optimalne rezultate specifičnosti in senzitivnosti.
Po (Youden 1950) sta optimalna senzitivnost in specifičnost doseženi, ko je njuna vsota največja. To je v našem primeru doseženo pri vrednosti kreatinina 86.5, kjer imamo senzitivnost = 0.722 in specifičnost = 1 - 0.393 = 0.607, skupna vsota je 1.329.
3.3 Ujemanje med ocenjevlaci – koeficient kappa
Z SPSS preberemo podatke iz naloge za statistično analizo. To naredimo tako, da ustrezno datoteko s podatki izberemo z ukazom File -> Open-> Data…
Podatki so organizirani tako, kot je prikazano v spodnji tabeli:
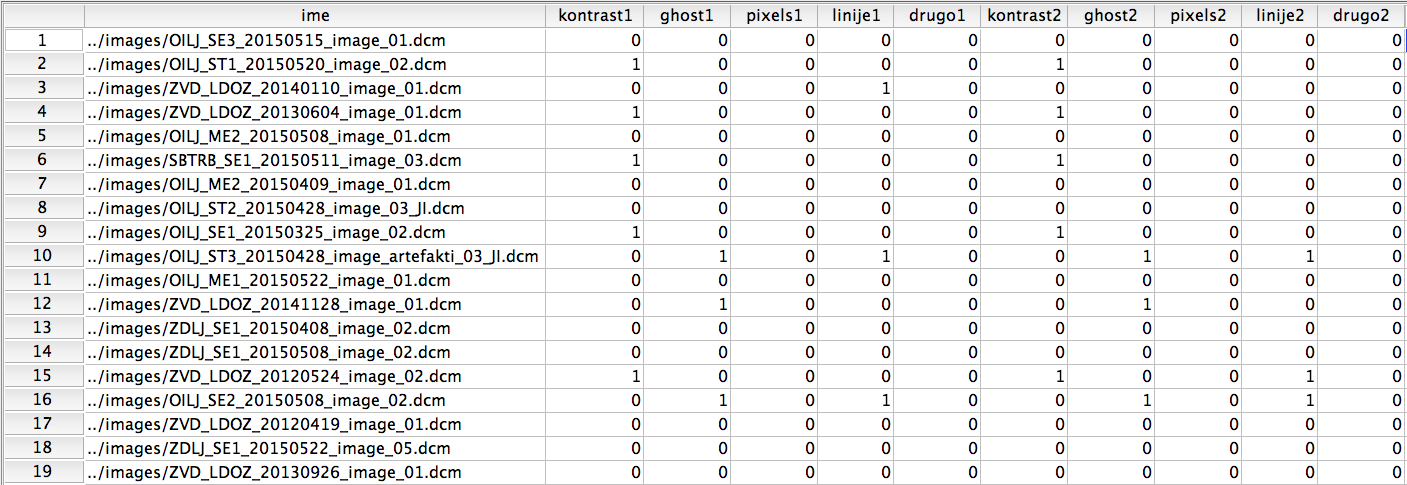
Vsaka mamografska slika je bila ocenjena s strani dveh označevalcev, ki sta na slikah označevala prisotnost artefaktov: kontrasta (spr. kontrast), ghost-a (spr. ghost), skupkov mrtvih pikslov (spr. pixels), linije (spr. linije) in drugo (spr. drugo). Označevalec 1 ima ocene zapisane v spremenljivkah z dodano številko 1, označevalec 2 pa v spremenljivkah z dodano številko 2. Če je na sliki prisoten artefakt, je vrednost spremenljivke 1, sicer je 0.
Ujemanje med označevalcema izračunamo z uporabo Cohenovega koeficienta kappa, ki ga najdemo v SPSS pri izračunu kontingenčne tabele. To naredimo z ukazom Analyze -> Descriptive Statistics -> Crosstabs…
V oknu Crosstabs izberemo ustrezne spremenljivke za izvedbo kontingenčne tabele. Najprej bomo preverili ujemanje označevalcev pri ocenjevanju kontrasta, zato za kontingenčno tabelo izberemo obe spremenljivki kontrasta. Ker bomo za mero ujemanja računali koeficient kappa, to izberemo z gumbom Statistics…, kjer označimo Kappa, kot je to prikazano v nadaljevanju:
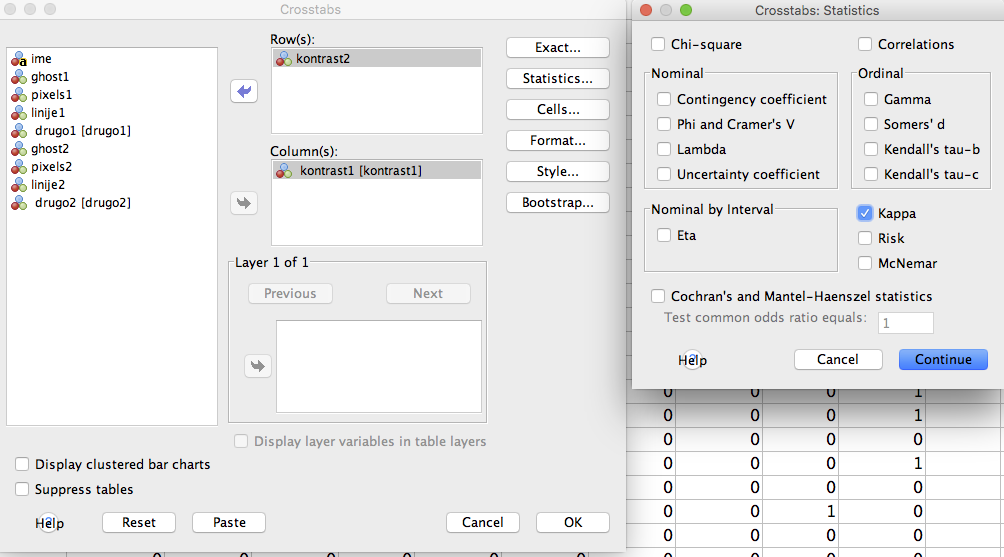
Enak postopek ponovimo za ujemanje označevalcev v ostalih artefaktih, le da namesto spremenljivk kontrasta vpišemo spremenljivke ghost, pixels, linije in drugo.
V izvedbenem oknu SPSS smo tako dobili kontingenčne tabele in koeficiente kappa za vsak artefakt posebej:
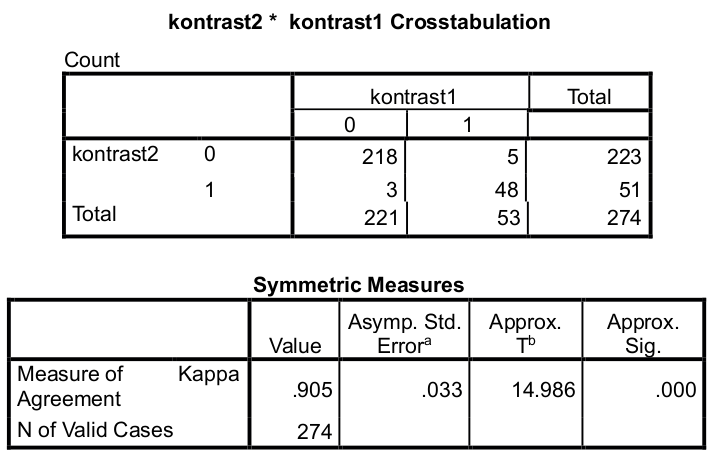
Artefakt kontrast:
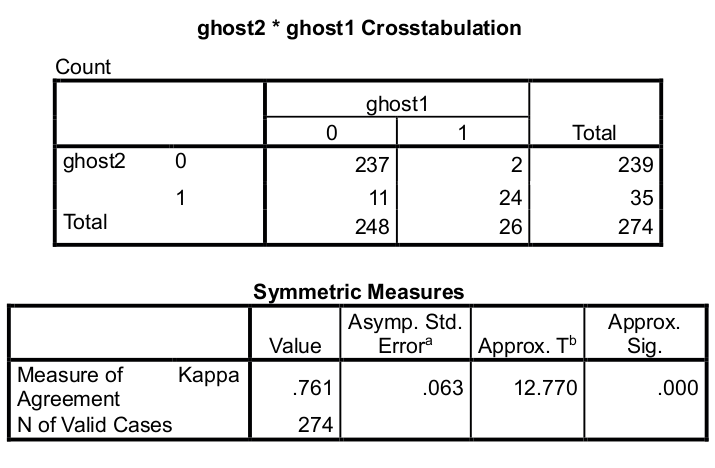
Artefakt ghost:
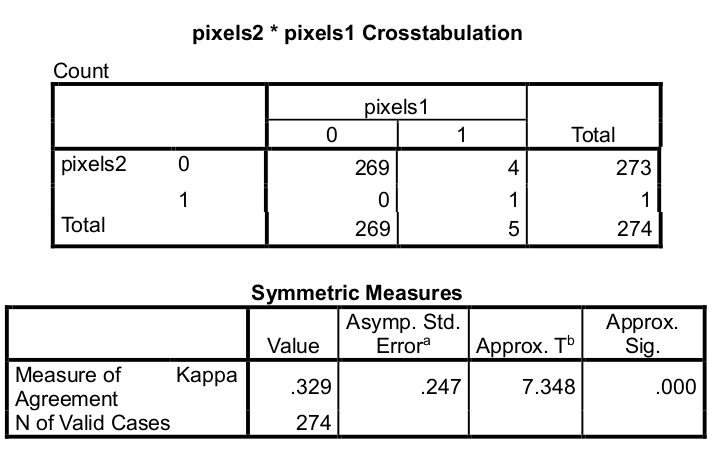
Artefakt piksli:
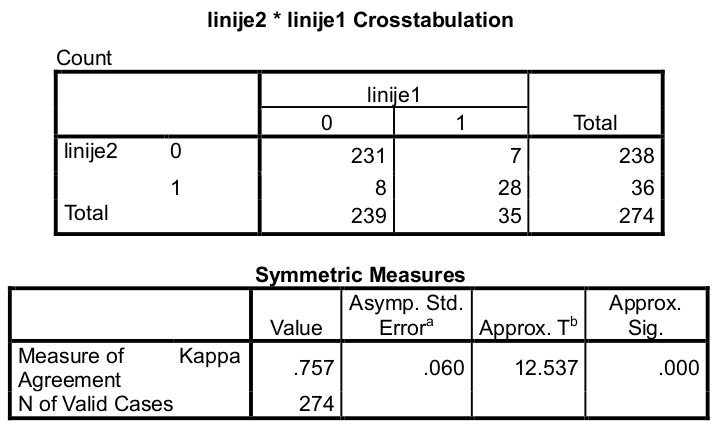
Artefakt linije:
Artefakt drugo:
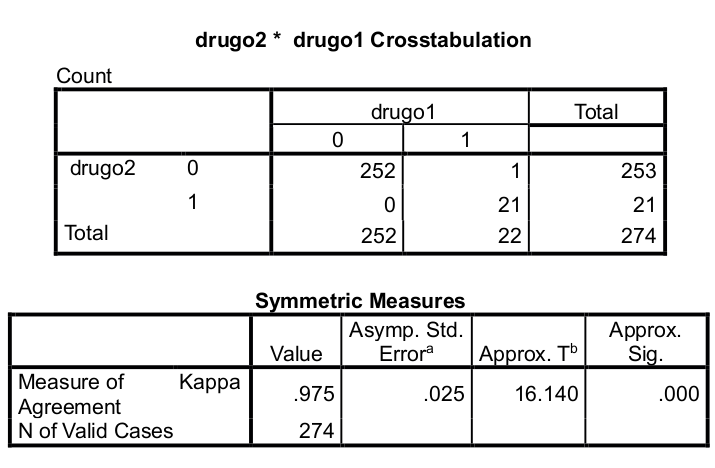
3.4 Koeficient kappa – več možnih oznak
Z SPSS preberemo podatke iz naloge za statistično analizo. To naredimo tako, da ustrezno datoteko s podatki izberemo z ukazom File -> Open -> Data… in preberemo Excelovo datoteko z izbiro File Type: Excel.
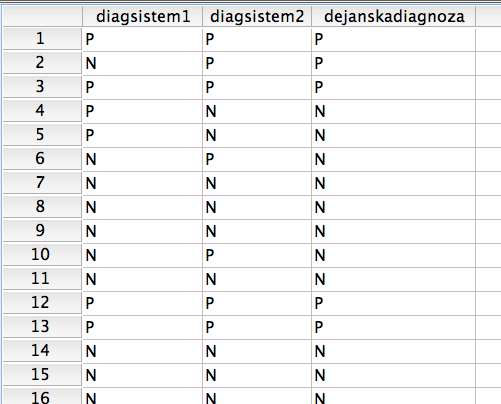
Podatki so organizirani tako, kot je prikazano v spodnji tabeli:
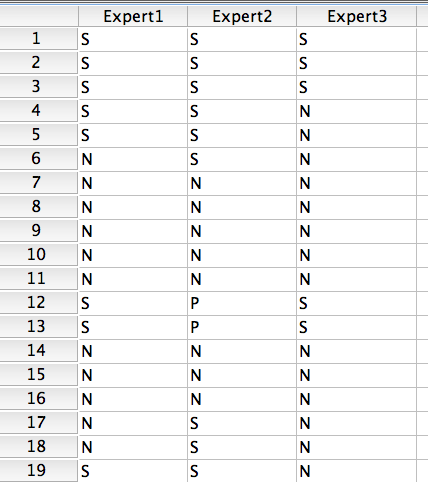
Imamo tri eksperte, ki so na podlagi radioloških slik podajali diagnoze: normalno (N), sumljivo (S), patologija (P). Tako so iz vsake slike pridobljene tri diagnoze.
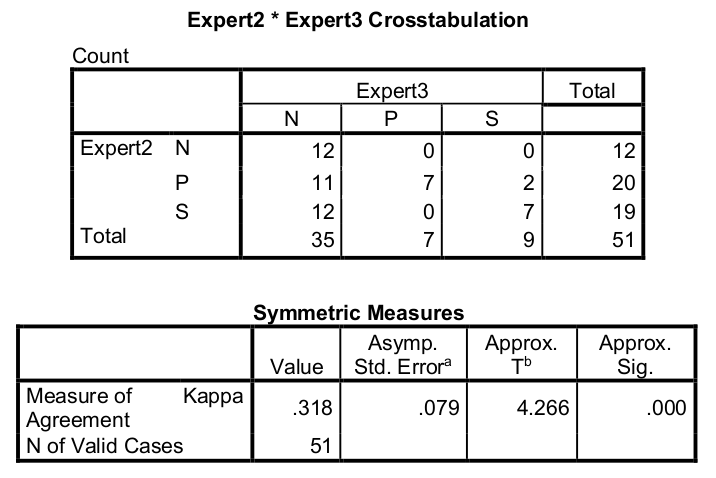
Ujemanje med eksperti bomo izračunali po parih: ekspert1 : ekspert2, ekspert1 : ekspert3, ekspert2 : ekspert3. Izračunali bomo koeficiente kappa in na podlagi tega določili, kdo se boljše ujema in kako.
To naredimo z ukazom Analyze -> Descriptive Statistics -> Crosstabs…
V oknu Crosstabs izberemo ustrezne spremenljivke za izvedbo kontingenčne tabele. Najprej bomo preverili ujemanje eksperta 1 in eksperta 2, zato za kontingenčno tabelo izberemo ustrezni spremenljivki.
Ker bomo za mero ujemanja računali koeficient kappa, z gumbom Statistics… odpremo okno, kjer označimo Kappa, kot je to prikazano v nadaljevanju:
Enak postopek ponovimo za ujemanje eksperta 1 in 3 ter eksperta 2 in 3, tako da za kontingenčno tabelo izberemo ustrezne spremenljivke.
V izvedbenem oknu SPSS smo tako dobili kontingenčne tabele in koeficiente kappa za vsak par ekspertov posebej:
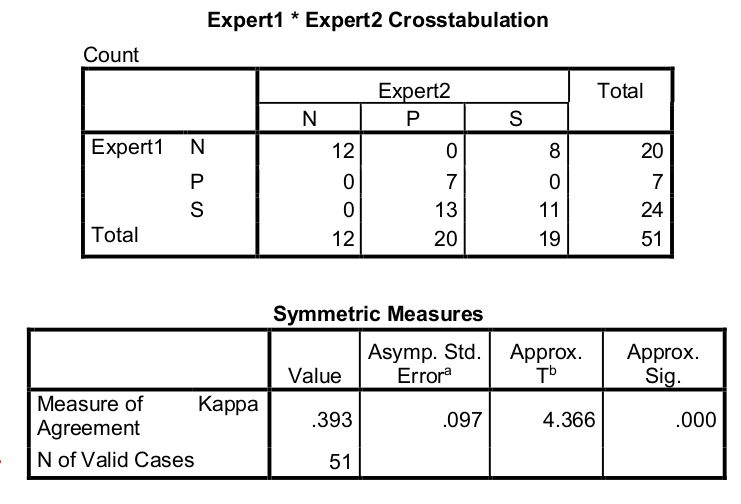
Ekspert 1 proti ekspert 2:
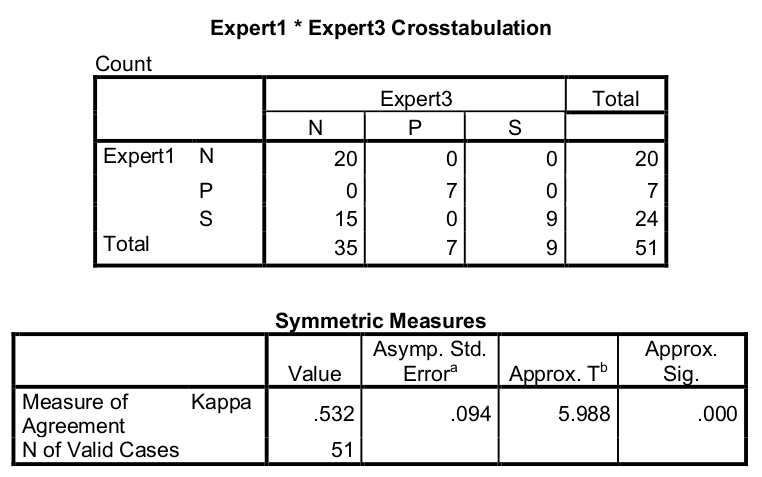
Ekspert 1 proti ekspert 3:
Ekspert 2 proti ekspert 3: